Spark on YARN两种运行模式的演示
前言
前面搭建好了Spark on YARN环境,接下来自然要使用这个集群,发挥它的计算性能。
最常规的使用方式就是提交程序,但由于Driver有两种运行方式,导致了Spark on YARN也有两种运行模式:Cluster(集群) 和 Client(客户端) 模式。
简单来讲,Cluster模式适用于生产环境,稳定性高,通讯效率高,但日志查看不方便;Client模式的日志输出在客户端,查看方便,但其稳定性受客户端进程影响,不适于生产环境。
本篇将演示两种运行模式提交程序的过程。
一、Client
1)和往常一样,先进入spark目录/export/servers/spark-3.2.0
2)输入指令,提交程序
#以客户端模式提交程序
bin/spark-submit --master yarn --deploy-mode client 程序#以上写法等同于 bin/spark-submit --master yarn 程序
3)去到4040端口查看
#任务结束前
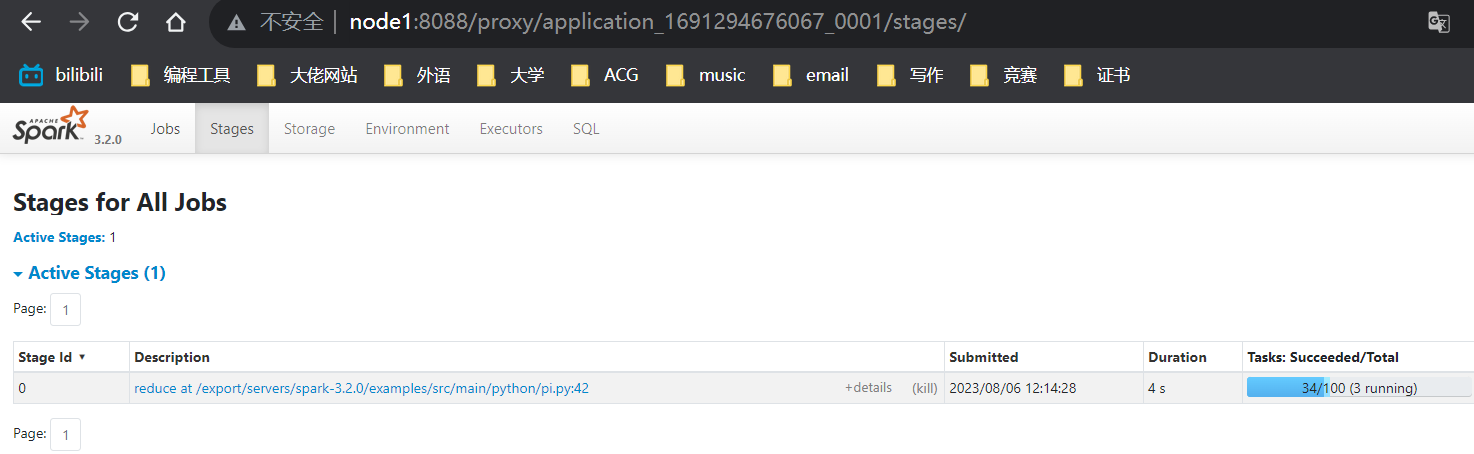
#任务结束后
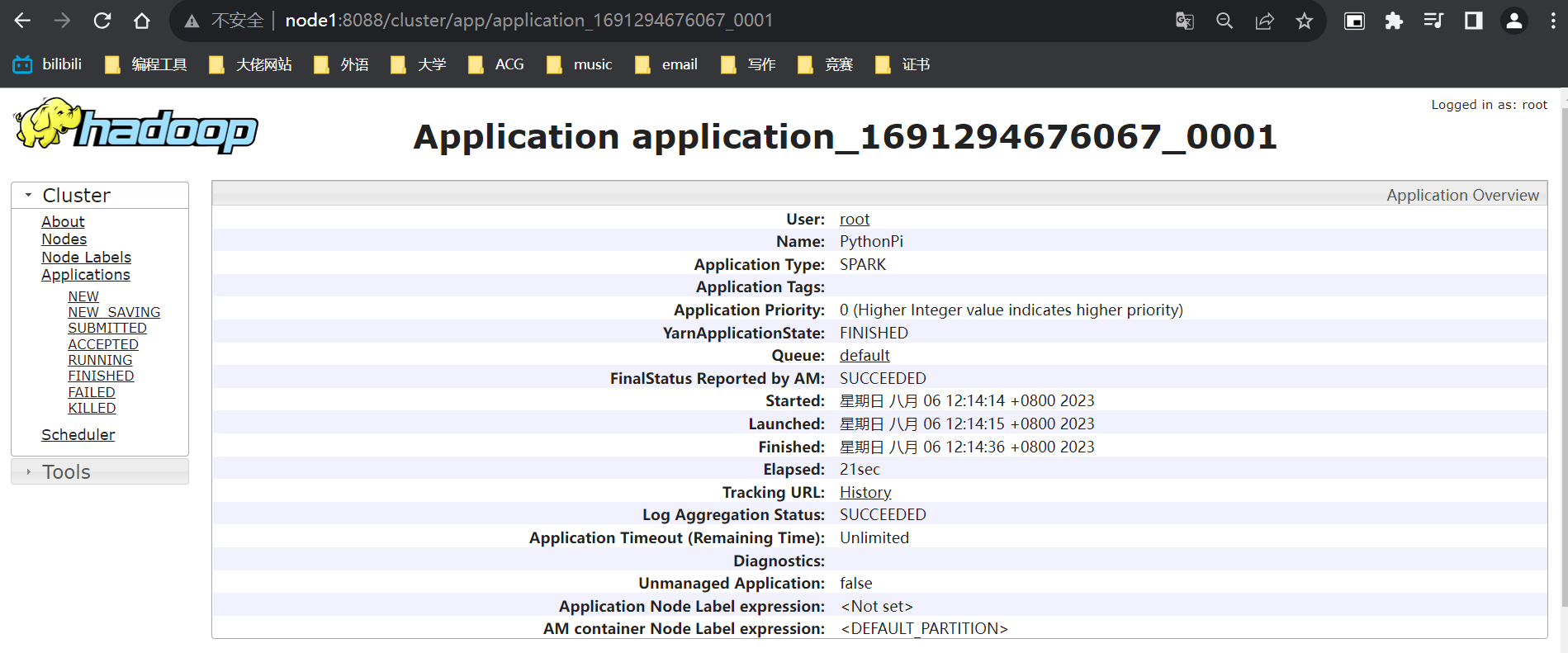
任务结束后,4040端口就没法展示了,但可以通过历史服务器来查看(18080)
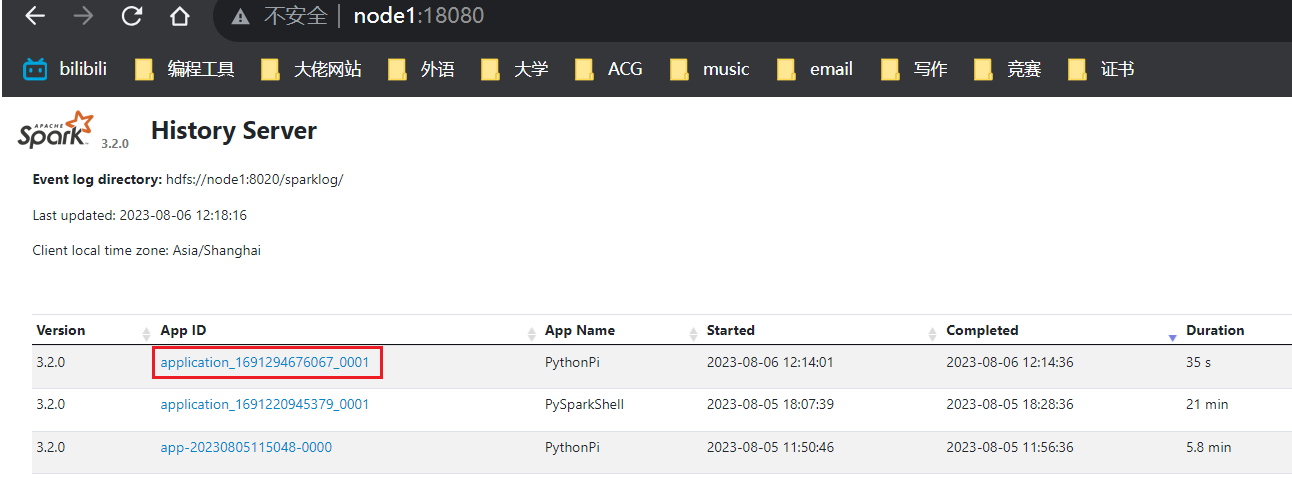
点击红框处,结果就是又回到了刚才页面
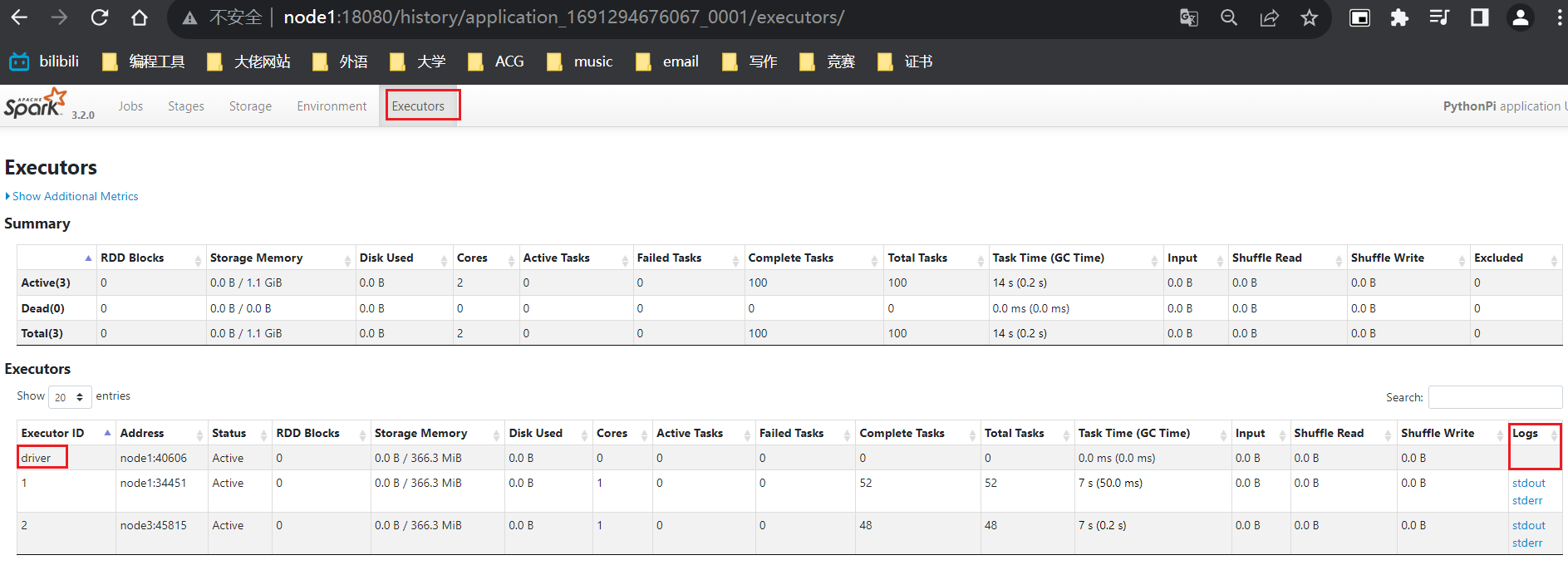

可以发现,driver在这个监控界面没有日志选项,计算结果在客户端上,这侧面说明了在客户端模型下,driver确实是运行到客户端上,而不是yarn的容器内部。所以以后,对于用submit提交程序,就没必要去4040端口查看了(任务结束后都会关闭),直接去历史服务端口查看。
二、Cluster
1)输入指令,提交程序
#以集群模式启动yarn
bin/spark-submit --master yarn --deploy-mode cluster 程序
2)查看yarn监控页面
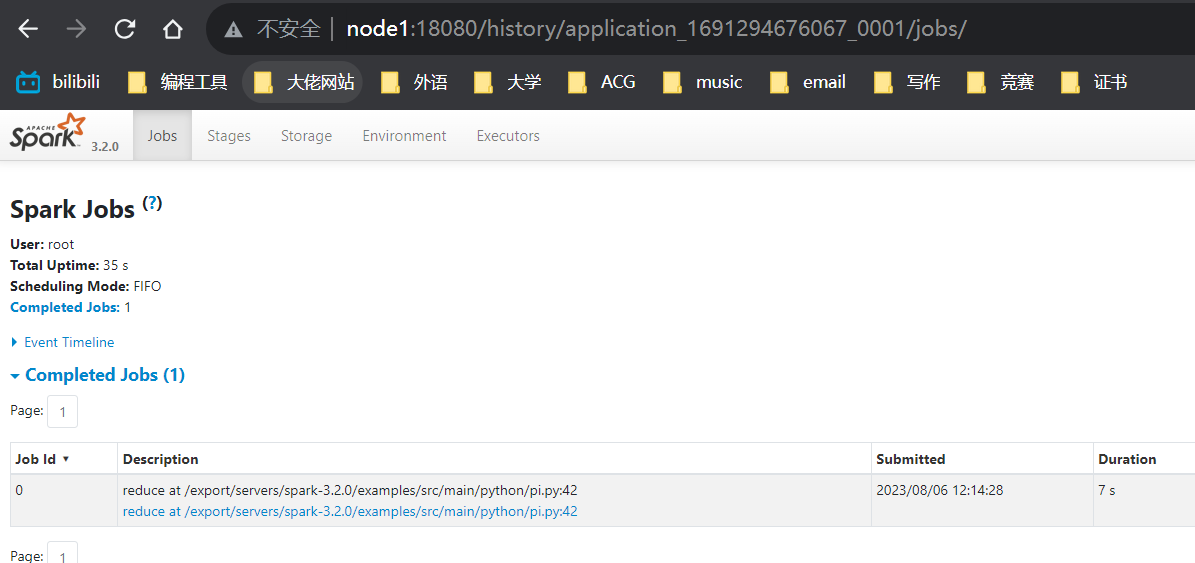
3)查看历史服务页面
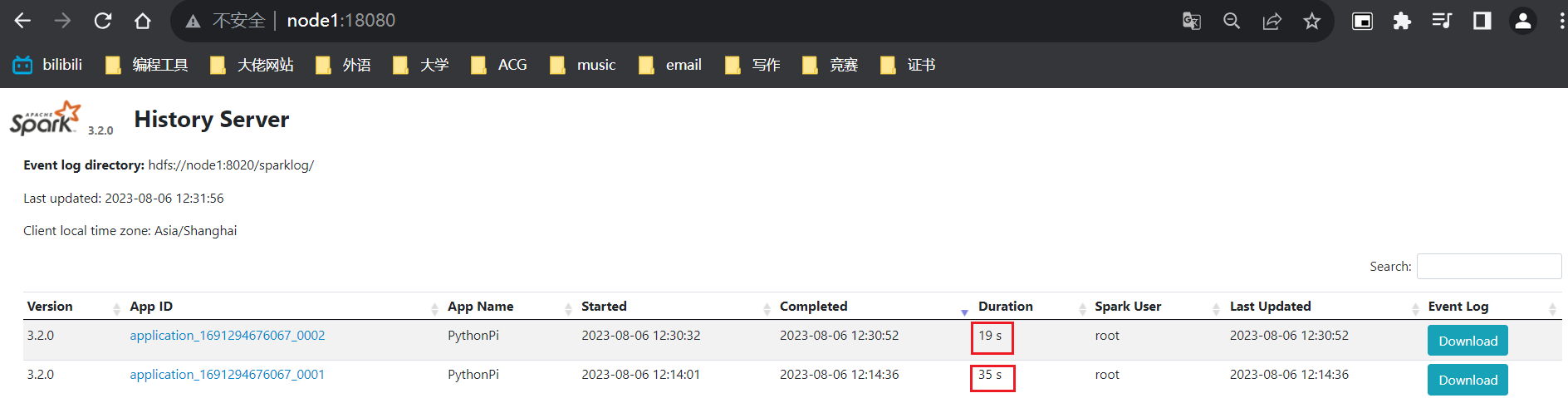
可以看出,cluster模式下运行程序确实比client模式要快


可以发现,driver有日志选项,客户端没有打印计算结果。说明cluster模式下的driver是运行在yarn的容器内部的。
那怎样才能查看计算结果呢?有3种方式:18080(历史服务页面) 和 8088(yarn的监控页面) ,以及通过指令从容器中抽离出日志(很麻烦)
我这里只介绍用页面的方法。
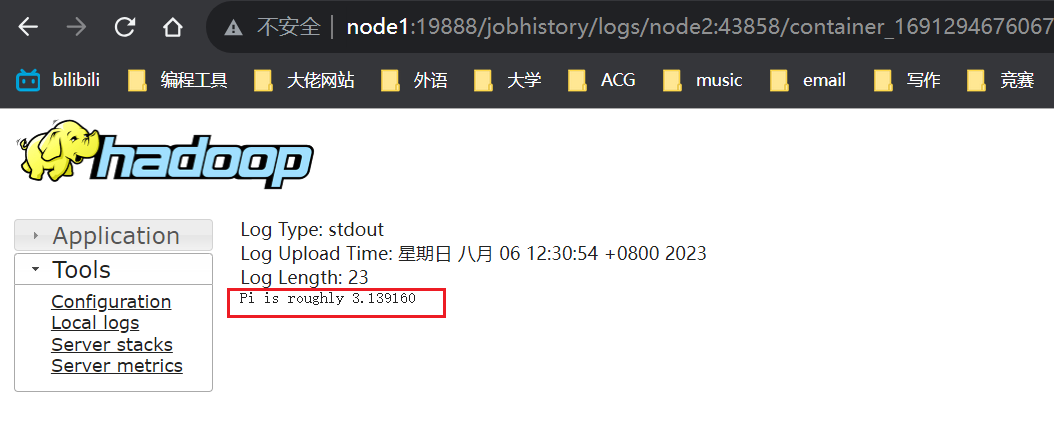
1、历史服务页面
我们点击driver对应的日志选项,就可以看到计算结果,

2、yarn监控页面
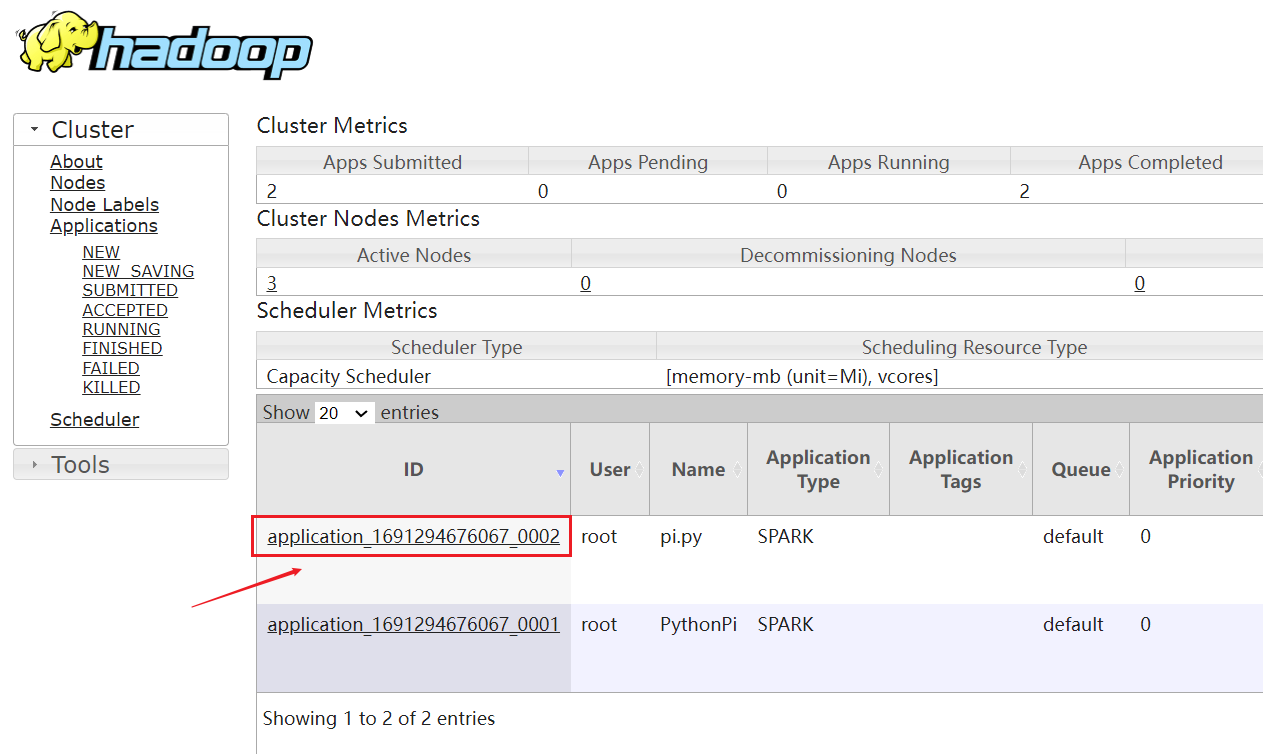
往下面一直翻,翻到底部,点击红框处

往下面一直翻,翻到底部

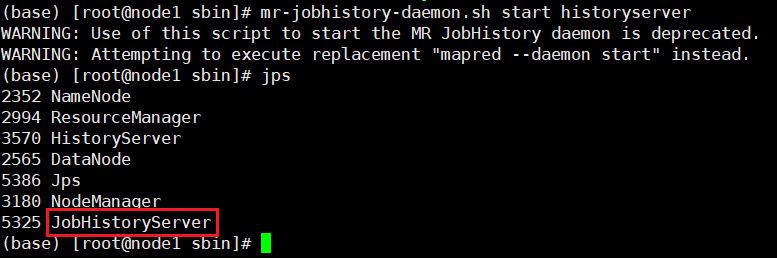
注意:如果两种方式你都无法打开,说明你没有启动yarn的历史服务器(JobHistoryServer),你仅仅只是启动了spark的历史服务器而已,用以下指令启动
#进入hadoop目录
cd /export/servers/hadoop-3.3.0
#开启服务(二选一),在node1(主节点)上执行
sbin/mapred --daemon start historyserver
或者
sbin/mr-jobhistory-daemon.sh start historyserver
三、两种模式运行流程图
1、Client

2、Cluster

标签:
相关文章
-
无相关信息