使用非递归构建无限级分类树
题目要求
现在我们拥有全国的省、市、区、县、镇、街道的行政区域信息表,比如中国>>广东省>>深圳市 >>南山区>>xx街道,请将这些信息构建成一棵树,根节点为全国,叶子节点为街道。
题目分析
为了方便模拟数据库表中的数据,在initData方法中生成国内城市的行政区域信息以便测试。
假设数据表信息如下:
数据对应的N叉树图
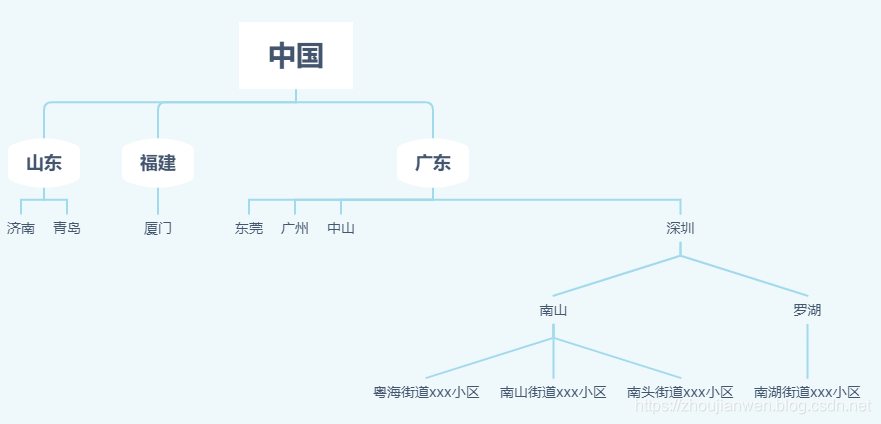
cid索引对应的N叉树图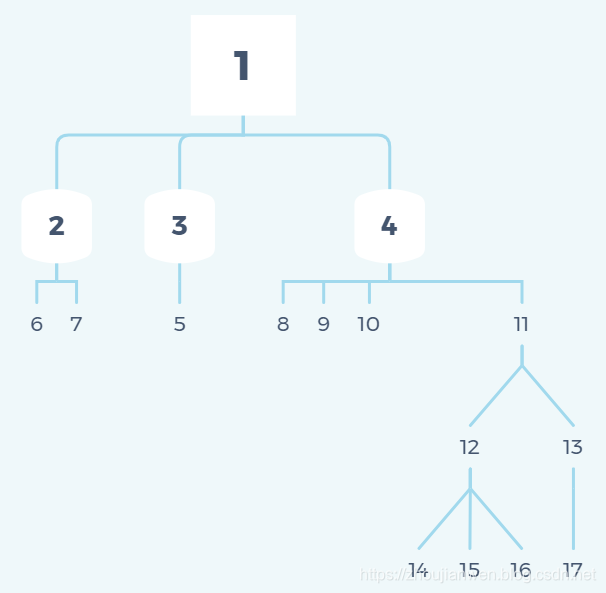
你可以使用递归和非递归方法处理数据,大多数面试在答题的时候都使用递归处理,在数据量不多且对性能没有要求可以这样作答。如果HR要求你使用非递归,就可以使用栈来处理,比较通用的做法是使用N叉树遍历,而二叉树的结点表示方法都是左、右孩子表示法,这种表示方法用在N叉树身上容易造成信息冗余,可以将结点的表示换成左孩子,右兄弟和bool,这个bool表示当前结点是否为最右的那个兄弟,但是这样操作层次遍历相对容易一些,换成先序遍历等其它方式的写法就有点麻烦了。为了方便遍历孩子结点,结点最基本的存储结构定义如下
class Node {
public:int val; //当前结点索引vector children; //孩子结点的集合Node() {}Node(int _val) {val = _val;}Node(int _val, vector _children) {val = _val;children = _children;}
};
递归遍历N叉树
节点定义
class Node {
public:int cid;//节点IDint pid;//父节点IDint level; //国省市区县镇string name;vector children;Node() { cid = 0; pid = 0; level = 0; }~Node() {if(this){children.clear();children.shrink_to_fit();cout << "释放资源" << endl;}}Node(int cid,int pid, int level ,string name) {this->cid = cid;this->pid = pid;this->level = level;this->name = name;}friend ostream& operator<<(ostream& output, const Node& t){return output << t.pid << ">>" << t.cid << ":" << t.level << ":" << t.name << endl;}
};
节点的操作
class Solution {
public:Solution() { cout << "Solution()" << endl;}~Solution() { cout << "Solution release" << endl; if (this) { this->vectorlist.clear();this->vectorlist.shrink_to_fit();this->ans.clear(); this->ans.shrink_to_fit(); } }vector ans;enum level{国, 省, 市 , 区 , 县, 镇, 街道};string levelName[7] = { "国", "省", "市" , "区" , "县", "镇","街道"};string spaceLevel[7] = { "",">>",">>>>",">>>>>>",">>>>>>",">>>>>>",">>>>>>>>" };vector vectorlist;vector initData() const{vector list;list.push_back(new Node(1, 0, 国, "中国"));list.push_back(new Node(2, 1, 省, "山东"));list.push_back(new Node(3, 1, 省, "福建"));list.push_back(new Node(4, 1, 省, "广东"));list.push_back(new Node(5, 3, 市, "厦门"));list.push_back(new Node(6, 2, 市, "济南"));list.push_back(new Node(7, 2, 市, "青岛"));list.push_back(new Node(8, 4, 市, "东莞"));list.push_back(new Node(9, 4, 市, "广州"));list.push_back(new Node(10, 4, 市, "中山"));list.push_back(new Node(11, 4, 市, "深圳"));list.push_back(new Node(12, 11, 区, "南山"));list.push_back(new Node(13, 11, 区, "罗湖"));list.push_back(new Node(14, 11, 街道, "粤海街道xxx小区"));list.push_back(new Node(15, 11, 街道, "南山街道xxx小区"));list.push_back(new Node(16, 11, 街道, "南头街道xxx小区"));list.push_back(new Node(17, 13, 街道, "南湖街道xxx小区"));return list;}void ShowLevelName(Node* node) const {cout << spaceLevel[node->level] << "["<cid<<"]"<< node->name <<"("<level]<<")"<< endl;}//递归Node* preorderChild(int cid) const{Node* node = getTreeNode(cid); //当前结点ShowLevel(node); //显示当前结点vector childNodes = getChildNode(cid); //获取当前结点的所有孩子结点的集合for(Node* cn : childNodes)//遍历孩子结点{Node* newNode = preorderChild(cn->cid);//递归node->children.push_back(newNode);//缓存孩子结点}return node;}Node* getTreeNode(int cid) const{for (int n = 0; n < vectorlist.size(); n++){if (vectorlist[n]->cid == cid){return vectorlist[n];}}}vector getChildNode(int pid) const{vector temp;for (int n = 0; n < vectorlist.size(); n++){if (vectorlist[n]->pid == pid){temp.push_back(vectorlist[n]);}}return temp;}
};
测试数据
int main()
{Solution *s = new Solution();s->vectorlist = s->initData(); //模拟数据库表的数据Node* node = s->preorderChild(1);delete node;delete s;system("pause");return 0;
}
显示结果
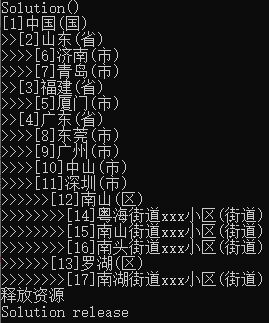
非递归遍历N叉树
N叉树遍历各个节点
//在Solution类内部添加非递归成员函数preorder
vector preorder(int root) const{vector ans;stack stk;Node* temp = getTreeNode(root); //1. 获取当前根结点if (temp)stk.push(temp); //2. 压入根结点while (!stk.empty()) {temp = stk.top(); //3. 获取栈顶结点ShowLevel(temp); //4. 显示当前结点信息ans.push_back(temp->cid);//缓存结点编号stk.pop();//5. 弹出栈顶结点vector childNodes = getChildNode(temp->cid); //6. 获取当前结点的孩子结点的集合int len = childNodes.size();for (int i = len - 1; i >= 0; i--) {if (childNodes[i])stk.push(childNodes[i]); //7. 入栈时,需要将子结点从右至左入栈,保证左侧子结点先遍历到}}return ans;}int main()
{Solution *s = new Solution();s->vectorlist = s->initData(); //模拟数据库表的数据vector ans = s->preorder(1); //从第一个结点(相对于根结点)开始遍历delete s;system("pause");return 0;
}
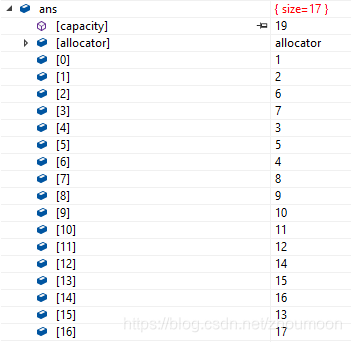
显示结果

preorder函数返回的先序遍历显示结果
vector内存分配的问题
如果在函数内部定义一个向量,那么该向量是分配在堆还是栈区域上?
vector fun() {vector sum = {1,2,3,4,5}; cout << &sum << endl; //0098FC08cout << &sum[0] << endl; //001386E0return sum;
}int main()
{vector list = fun(); cout << &list << endl; //0098FD7Ccout << &list[0] << endl; //001386E0
}
vector fun() {vector* sum = new vector();sum->push_back(1);sum->push_back(2);sum->push_back(3);sum->push_back(4);sum->push_back(5);cout << sum << endl; //001CFD08cout << &sum[1] << endl; //009B4AD8return sum;
}int main()
{vector list = fun();cout << list << endl; //001CFE7Ccout << &list[1] << endl; //009B4AD8system("pause");return 0;
}
由此可知
sum变量保存在栈上,对象(即实际的数据)保存在堆上
sum变量保存对象的引用,销毁变量时释放对象的引用,引起析构函数的调用
再来一个例子
Node* fun2(){Node* list = new Node();return list;
}int main()
{Node* p = fun2();delete p;system("pause");return 0;
}
函数在执行完毕之后,指针变量list指向的堆内存的实际数据并没有被释放掉,只能delete p释放被占用的资源,但是函数内的指针变量list会随函数生存周期结束而被销毁,销毁指针变量时会释放指针变量原来占用的内存区域。
换另一种写法
Node fun(){Node list;cout<<&list<输出结果
00EFFA6C
释放资源 //析构函数
00EFFC08
fun函数在返回数据之前,自动调用Node类的析构函数释放资源,其实还有一次调用析构函数没有显示出来,就是在main函数执行结束之前,变量p也会再次调用Node类的析构函数。虽然这样操作不会产生问题,但是这样做会容易重复对同一个资源位置释放两次操作,对于深拷贝和浅拷贝而言特别重要,之后会重点记录学习笔记。
参考
n叉树遍历 《算法导论》10.4-4 10.4-6
https://blog.csdn.net/weixin_30336061/article/details/99870489
标签:
相关文章
-
无相关信息