向量数据库实战详解
为什么需要向量数据库
以NLP的相似问题场景为例。当我们将一个问题通过模型转化成了embedding向量,我们想要找到与这个问题相似的问题,也就是想要找到与embedding向量相似的向量。基本的做法之一,就是遍历备选向量与embedding向量做余弦相似度计算,然后按照计算出的余弦相似度排序,找出最相似的top N。基于向量检索的目的,向量数据库应运而生。向量数据库提供了一种高性能、高可用的查找方式。
接下来,以Annoy和Milvus两种向量数据库的实战为例详解。
Annoy
Annoy 安装很简单:
pip install --user annoy
Annoy是一个基于文件的向量数据库,最主要的三个操作如下:
a.save(fn, prefault=False) saves the index to disk and loads it (see next function). After saving, no more items can be added.
a.load(fn, prefault=False) loads (mmaps) an index from disk. If prefault is set to True, it will pre-read the entire file into memory (using mmap with MAP_POPULATE). Default is False.
a.unload() unloads.
a.get_nns_by_vector(v, n, search_k=-1, include_distances=False) same but query by vector v.
save是保存成索引文件,load是加载索引问题,unload是卸载索引文件。
这里面需要注意的一个关键问题是:
索引文件被进程load以后,才可以进行检索等操作get_nns_by_vector。如果索引文件被某进程A load,那么同时还可以被B load,即支持多进程加载索引文件。可是,这时如果索引内容有变化,想要重新save索引文件,就会报错,即load中的索引文件是无法被save的。只有把检索业务暂停,所有加载索引的进程unload掉索引,才能save更新索引,然后,所有进程再load新的索引,继续检索业务。不难看出,annoy本质上是一个静态索引,不支持动态更新索引。如果,我们业务场景里,需要检索的数据是“千年不变”,那么Annoy是一个上手容易,不需要额外部署开销的选项。
https://github.com/spotify/annoy/issues/191
annoy不支持实时刷新,不支持删除
而实际的业务数据是经常实时变化的,针对索引实时变化这个需求,我们接下来介绍milvus。
Milvus
milvus不同版本差异还比较大,对应的api是不同的,使用方法也是不同的,需要根据实际需求认真选择。在这里,我最终选择的是milvus 1.1.1,接下来我会解释原因。
milvus 1.1.1
安装服务端
sudo docker pull milvusdb/milvus:1.1.1-cpu-d061621-330cc6
sudo mkdir -p /home/$USER/milvus/conf
cd /home/$USER/milvus/conf
sudo vi server_config.yaml
https://raw.githubusercontent.com/milvus-io/milvus/v1.1.1/core/conf/demo/server_config.yaml
安装客户端
pip3 install pymilvus==1.1.2
pymilvus index params — pymilvus 0.2.14 documentation
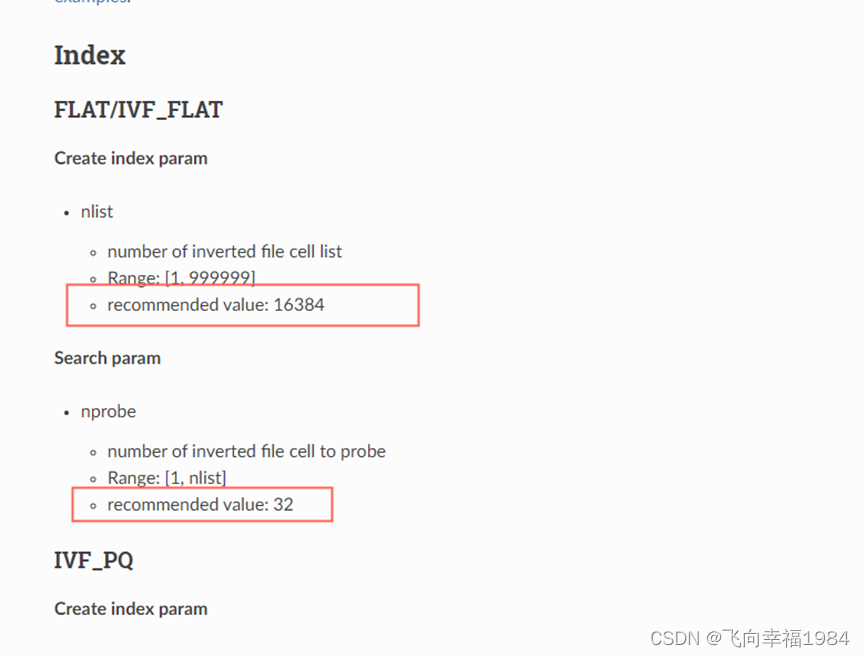
运行服务端
sudo docker run -d --name milvus_cpu_1.1.1
-p 19530:19530
-p 19121:19121
-v /home/$USER/milvus/db:/var/lib/milvus/db
-v /home/$USER/milvus/conf:/var/lib/milvus/conf
-v /home/$USER/milvus/logs:/var/lib/milvus/logs
-v /home/$USER/milvus/wal:/var/lib/milvus/wal
milvusdb/milvus:1.1.1-cpu-d061621-330cc6
需要注意
相同的id会重复插入
https://github.com/milvus-io/pymilvus/issues/464
目前重复id需要靠用户自己保证,不能重复插入
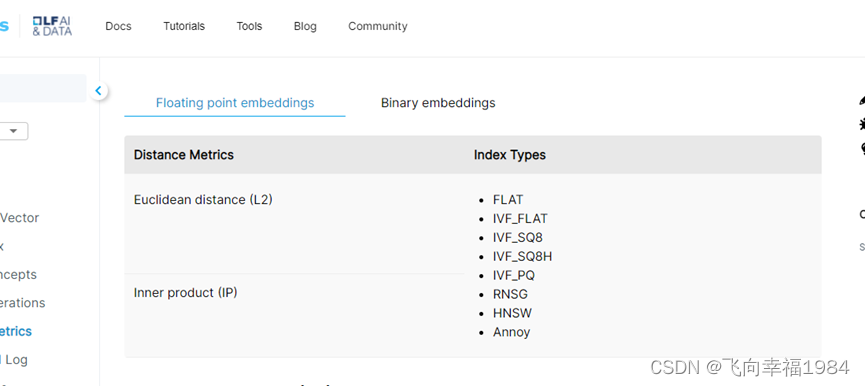
如何选择metric_type
Similarity Metrics - Milvus documentation
Milvus距离计算公式
先比对下annoy 和 milvus之间的距离计算方法
annoy
milvus
angular
L2、IP
milvus不支持angular,我们NLP场景选择IP。
SBERT是用cosine-sim,angular 是基于cosine-sim的进一步计算
https://en.wikipedia.org/wiki/Cosine_similarity
a = AnnoyIndex(f, metric):f 指的是向量的维度,metric 表示度量公式。在这里,Annoy 支持的度量公式包括:”angular”, “euclidean”, “manhattan”, “hamming”, “dot”;

使用IP作为距离计算方法,要求保存到milvus的向量是进行归一化后的向量。
https://www.tensorflow.org/api_docs/python/tf/math/l2_normalize
milvus 2.0.2
安装服务端
pymilvus · PyPI
Install Milvus Standalone - Milvus documentation
sudo apt-get install docker-compose-plugin
milvus 2.0安装_xiedelong的博客-CSDN博客_pymilvus安装
sudo docker search milvus
sudo docker pull milvusdb/milvus
安装客户端
pip3 install pymilvus==2.0.1
运行服务端
wget https://github.com/milvus-io/milvus/releases/download/v2.0.2/milvus-standalone-docker-compose.yml -O docker-compose.yml
sudo apt-get update
sudo apt-get install docker-compose-plugin
sudo docker compose up -d
milvus 2.0里能存放数字scalar
sudo docker compose down —— 关闭服务端
需要注意
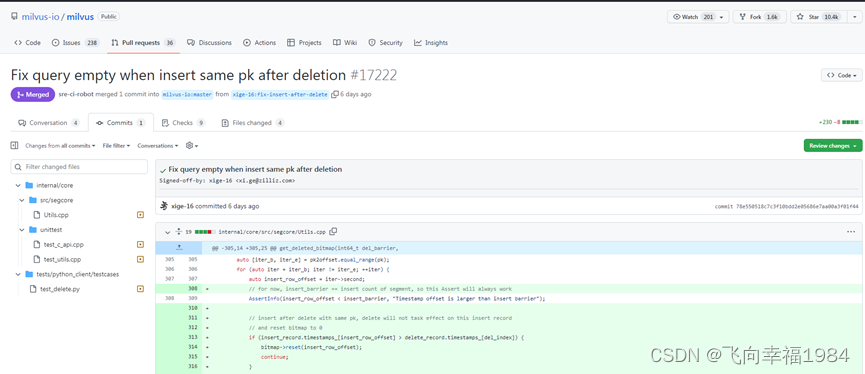
同pk数据删除后无法恢复Bug
从milvus中删除pk为key的数据,query查不到了,那么同样的pk为key的数据再次insert后,query也查不到的,即同一个键值只能插入一次,删除后,再插入无法恢复。这是近期才修复的一个bug,没有对应的docker正式版本可以安装使用。所以,2.0.2这个版本对于我当前的业务场景来说,暂时不可用,我选择了milvus 1.1.1。
https://github.com/milvus-io/milvus/pull/17222
distance误差
在使用中我发现A数据插入后,第一次查询A时,能够精确找到A,并且distance是0。可是当删除A以后,再次插入A,也能找到A,只不过distance不是0了,会有非常非常小的误差。这种情况,无论是milvus 2.0.2 还是milvus 1.1.1都一样。通过在milvus 2.0.2中query方法获取embeddings可以看到,embeddings数据在存入时,不是保留小数点后所有数据,而是存在一个截取,也就是你输入的是 0.xxxxxx yyyyy,最后实际保存的是0.xxxxxx,后面被截断了。推测误差可能跟截断有关。因为误差很小,影响暂时可以忽略。
对比
milvus 1.1.1 部署更简单,只有一个服务启动,支持的功能比较单一;milvus 2.0.2 依赖的容器部署更多更复杂,支持的功能也更全面;milvus 2.0.2目前来看还没有完全稳定,还有无法忽视的bug存在,因此我选择milvus 1.1.1。
参考
https://github.com/spotify/annoy
一文带你了解Annoy!
Installation Overview - Milvus documentation
近似最近邻搜索算法 ANNOY(Approximate Nearest Neighbors Oh Yeah) | ZHANG RONG
标签:
相关文章
-
无相关信息