Encoding Human Domain Knowledge to Warm Start Reinforcement Learning
目录
相关资料
- 论文链接:Encoding Human Domain Knowledge to Warm Start Reinforcement Learning
- 代码地址:算法地址ProLoNets
1.研究动机是什么
在许多强化学习任务中,当面临新的挑战时,智能体往往从“零”开始学习,忽略了许多可以从领域专家那里获得的丰富的现成知识。这些知识可以帮助智能体快速启动学习过程,减少不必要的探索,加速智能体训练,缩短训练时间。
2.主要解决了什么问题
使用专家知识构造决策树策略来初始化神经网络,通过这种方式对智能体进行指导,起到warm-start的作用;同时,随着训练的进行,决策树会不断生长,增加新知识,最终超过用来初始化的专家知识。
3.所提方法是什么
作者提出了一种新的强化学习技术,通过人工初始化神经网络权重和结构。将领域知识直接编码进入神经网络决策树,并通过策略梯度更新对该知识进行改进。同时,随着训练的进行,神经网络决策树不断生长,发现新知识,最终超过专家知识。
3.1总体流程
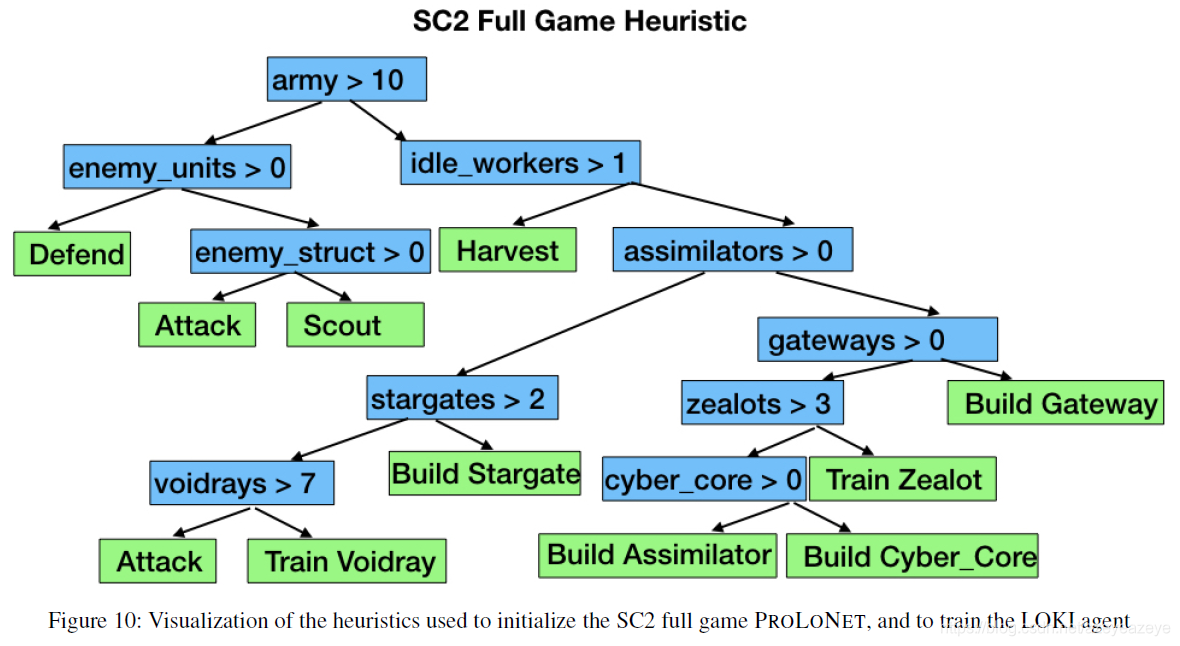
总体流程如图所示:1.需要提供分层形式的决策规则集合。这些策略是通过简单的用户交互来指定指令的。2.每条规则被转换为网络参数,每条规则的表达式为权重和判断条件为偏差,形成初始化的决策树神经网络。3.利用初始化网络与环境进行交互收集数据,更新网络参数,对知识改进。4.每次迭代更新,检查决策树纯度,当纯度过低,增长树,原来的树节点复制网络参数,新的节点随机初始化参数,形成新的决策树神经网络。重复3-4,直至训练结束。

3.2PROLONET决策树网络
首先用户需要提供分层形式的决策过程。随后用户的决策过程被转换为神经网络,每条规则由网络权重 ω n → ∈ W overrightarrow{omega_n}in W ωn ∈W和比较值(偏差) c n ∈ C c_n in C cn∈C表示。如图传统的决策树和PROLONET。决策节点变成线性层,叶子节点变成动作概率,最终的输出是路径概率加权的叶子之和。

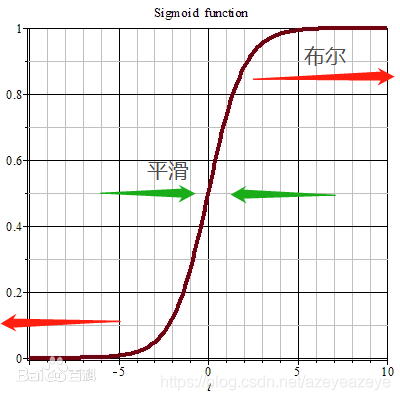
对于每一个决策节点 D n D_n Dn来说,整个网络被表示为 D n = σ [ α ( w ⃗ n T ∗ X ⃗ − c n ) ] D_{n}=sigmaleft[alphaleft(vec{w}_{n}^{T} * vec{X}-c_{n}right)right] Dn=σ[α(w nT∗X −cn)],其中, X → overrightarrow{X} X 是输入数据,为环境状态, σ sigma σ是sigmoid函数, α alpha α是用于抑制决策节点的置信度,对树的置信度越低,决策的不确定性就越大,从而导致更多的探索。 w ⃗ n T ∗ X ⃗ − c n vec{w}_{n}^{T} * vec{X}-c_{n} w nT∗X −cn计算状态是否满足不等式, α alpha α与 σ sigma σ进行放缩。 α alpha α值大强调比较器和加权输入之间的差异,往中心反方向移动,概率区分度增大,从而推动树更布尔。 α alpha α值越低,差异向中心方向移动,概率接近0.5,树越平滑,而 α = 0 alpha=0 α=0则产生一致的随机决策 。下面将以Cartpole为例,对文章提出的方法详细解读。Cartpole的状态空间是4维向量{cart position, cart velocity, pole angle, pole velocity};动作空间是2维向量{left, right}。
3.2.1PROLONET初始化
现有一条规则:如果小车的位置在中心的右边,向左移动;否则,向右移动,中心为0。用户指明位置是输入4维状态特征的第一个元素。初始化决策节点 D 1 D_1 D1,权重和偏差为 w 1 → = [ 1 , 0 , 0 , 0 ] overrightarrow{w_{1}}=[1,0,0,0] w1 =[1,0,0,0], c 1 = 0 c_{1}=0 c1=0如Alg1的5-8。接下来的11-13创造一个新的叶节点 l 1 → = [ 1 , 0 ] overrightarrow{l_{1}}=[1,0] l1 =[1,0]表示向左, l 2 → = [ 0 , 1 ] overrightarrow{l_{2}}=[0,1] l2 =[0,1]表示向右。最后,初始化路 Z ( l 1 → ) = D 1 Zleft(overrightarrow{l_{1}}right)=D_{1} Z(l1 )=D1和 ( l 2 → ) = ( ¬ D 1 ) left(overrightarrow{l_{2}}right)=left(neg D_{1}right) (l2 )=(¬D1)。由此产生的智能体动作的概率分布是一个softmax函数 ( D 1 ∗ l 1 → + ( 1 − D 1 ) ∗ l 2 → ) left(D_{1} * overrightarrow{l_{1}}+left(1-D_{1}right) * overrightarrow{l_{2}}right) (D1∗l1 +(1−D1)∗l2 )。处理完所有决策节点后,每个节点 D n D_n Dn的值表示该条件为TRUE的可能性, ( 1 − D n ) (1-D_n) (1−Dn)为FALSE。有了这些可能性,然后乘出不同路径到所有叶节点的概率。每个叶节点包含了一条路 z ∈ Z z in Z z∈Z,这是一组决策节点,应该是TRUE或FALSE,以便达到叶节点 l l l,计算每个输出动作的先验权值。例如,在上图中, z 1 = D 1 ∗ D 2 z_1=D_1*D_2 z1=D1∗D2, z 3 = ( 1 − D 1 ) ∗ D 3 z_3=(1-D_1)*D_3 z3=(1−D1)∗D3.在叶子节点中,通过将到达的概率乘以在叶节点内的输出的先验权重来确定。在计算每一个叶子的输出后,这些叶子被求和并通过一个softmax函数传递,以提供最终的输出分布。

3.2.2PROLONET推理
假设小车当前状态为 X = [ 2 , 1 , 0 , 3 ] X=[2,1,0,3] X=[2,1,0,3],决策树只有1个决策节点2个叶节点。根据决策节点的公式,在经过第一个节点 D 1 D_1 D1之后, σ ( [ 1 , 0 , 0 , 0 ] ∗ [ 2 , 1 , 0 , 3 ] − 0 ) = 0.88 sigma([1,0,0,0] *[2,1,0,3]-0)=0.88 σ([1,0,0,0]∗[2,1,0,3]−0)=0.88,这意味着“基本是正确的"。这个概率通过各自的路径传播到两个叶子节点,使得网络的输出概率为
P out = L 1 → ( σ 1 ∗ σ 2 ) + L 2 → ( σ 1 ∗ ( 1 − σ 2 ) ) ) = 0.88 ∗ [ 1 , 0 ] + ( 1 − 0.88 ) ∗ [ 0 , 1 ] ) = [ 0.88 , 0.12 ] P_{text {out }} =overrightarrow{L_{1}}left(sigma_{1} * sigma_{2}right)+overrightarrow{L_{2}}left(sigma_{1} *left(1-sigma_{2}right)right))\ =0.88 *[1,0]+(1-0.88) *[0,1])=[0.88,0.12] Pout =L1 (σ1∗σ2)+L2 (σ1∗(1−σ2)))=0.88∗[1,0]+(1−0.88)∗[0,1])=[0.88,0.12]
因此,智能体以 0.88 0.88 0.88的概率选择第一个动作,以 0.12 0.12 0.12概率选择第二个动作。

参照文中的Cartpole启发式算法,绘制了PROLONET网络,如下所示。与作者提供的代码中建立的决策树不同,少1个决策节点和1个叶节点。转换规则如下:if条件语句不等号左用权重 ω n → overrightarrow{omega_n} ωn 表示,对应位置元素为1,其余为0;不等号右用 c n c_n cn表示;若符号为小于, ω n → overrightarrow{omega_n} ωn 和 c n c_n cn都乘 − 1 -1 −1.

在实际应用时,每个叶子节点会保存从初试节点到该叶子节点的路 z ∈ Z z in Z z∈Z的信息,方便计算 L i → overrightarrow{L_{i}} Li
3.2.3PROLONET动态增长
为了使PROLONET体系结构能够在其初始定义的基础上继续增长,作者引入了一个动态增长过程,在Algorithm2和图3中描述了这个过程。初始化之后,PROLONET智能体会维护决策树网络两个副本。第一个是初始化的浅层网络,第二个是动态增长的深层网络,动态增长时,第二个网络每个叶子节点转化为随机初始化决策节点,并随机初始化决策节点的两个新的叶子节点。在每一Episode之后,在浅层和深层的网络上更新网络。更新后,比较浅层的叶子的熵和深层叶子的熵,当较深的叶子比较浅的叶子不均匀时,有选择地加深(第3-7行)。作者认为这种动态增长机制能提高稳定性和平均累积报酬。这会产生更多的参数学习更复杂的策略,但会增加随机性和不确定性,降低智能初始化的效用。由于智能体与环境交互,它依赖于较浅的网络来产生动作,因为较浅的网络代表了人类的领域知识。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dE2kgHqB-1627308462430)(E:文档TyporaEncoding Human Domain Knowledge to Warm Start Reinforcement Learningimagesclip_image004.gif)]](https://img-blog.csdnimg.cn/54bd7b10227a439db5b222f007ed4350.gif?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2F6ZXllYXpleWU=,size_16,color_FFFFFF,t_70#pic_center)
决策树动态增长机制依据ID3,以信息增益为准则来优化决策树。当浅层网络发现了一个局部最小值 l 1 = [ 0.5 , 0.5 ] l_{1}=[0.5,0.5] l1=[0.5,0.5],我们希望决策树的决策节点对样本的分类越清晰越好,即纯度越来越高。显然, l 1 = [ 0.5 , 0.5 ] l_{1}=[0.5,0.5] l1=[0.5,0.5]不满足要求,对向左向右走模棱两可,需要深化决策树。当深化的网络发现了 l 3 = [ 0.9 , 0.1 ] l_{3}=[0.9,0.1] l3=[0.9,0.1]和 l 4 = [ 0.1 , 0.9 ] l_{4}=[0.1,0.9] l4=[0.1,0.9],对向左向右走划分的十分清晰,此时节点纯度较高。我们用信息熵 H ( l i ) Hleft(l_{i}right) H(li)对树的这种特性进行度量。
H = ∑ p l o g 2 p H=sum plog_2p H=∑plog2p
H H H的值越小,则纯度越高,树的分类效果越好。如Algorithm2中8行,浅层的决策树的熵 H ( l i ) > ( H ( l d 1 ) + H ( l d 2 ) + ϵ ) Hleft(l_{i}right)>left(Hleft(l_{d 1}right)+Hleft(l_{d 2}right)+epsilonright) H(li)>(H(ld1)+H(ld2)+ϵ),说明深化后树熵减小,信息增益,纯度提高,决策更准确。

4.关键结果及结论是什么
作者对提出的RL框架进行了两个互补的评估。第一个是具有专家初始化的受控研究。第二个评估是一个用户研究。这里主要介绍第一组评估实验。实验环境为《星际争霸2》(SC2)中宏观和微观战斗以及OpenAl Gym月球登陆器和推车杆环境。对比算法:除了上面所述的具有专家初始化PROLONET,还评估了多层感知器(MLP)和长短期记忆(LSTM) 智能体,带有随机初始化的PROLONET (random PROLONET),启发式(Heuristic)算法,LOKI框架下训练的IL agent和DJJINN。LOKI代理使用与初始化PROLONET智能体相同的启发式进行监督。DJJINN最初的框架需要一个决策树学习标签数据集,作者进行了修改,允许初始化与手工决策树,为了比较,DJJINN初始化与PROLONET相同。
4.1实验环境及对比算法
4.1.1 Cart Pole
PPO RMSProp γ=0.99 lr=0.01 parallels=2
PROLONET:
α = 1 α=1 α=1 ε = 0.19 ε=0.19 ε=0.19 决策节点9,叶子节点11Random PROLONET强化参数:
PPO RMSProp γ=0.99 lr=0.01 parallels=2
LOKI强化参数:
PPO RMSProp γ=0.99 lr=0.01 parallels=2
模仿次数N=200DJJINN同 PROLONETLSTMPPO ReLU
LSTM:
3-layer 4x4 – LSTM(4x4) – 4x2MLPPPO ReLU
MLP:
3-layer 4x4 – 4x4 – 4x2Heuristic(规则)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0td1tBBA-1627308462431)(E:文档TyporaEncoding Human Domain Knowledge to Warm Start Reinforcement Learningimagesclip_image012.png)]](https://img-blog.csdnimg.cn/bbed1d7efcb24ed9ac6d28ad16ad93ec.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2F6ZXllYXpleWU=,size_16,color_FFFFFF,t_70)
4.1.2 Lunar Lander
PPO RMSProp γ=0.99 lr=0.01 parallels=4 batch_size=4
PROLONET:
α = 1 α=1 α=1 ε = 0.19 ε=0.19 ε=0.19 决策节点14,叶子节点15Random PROLONET强化参数:
PPO RMSProp γ=0.99 lr=0.01 parallels=4 batch_size=4
LOKI强化参数:
PPO RMSProp γ=0.99 lr=0.01 parallels=4 batch_size=4
模仿次数:N=300DJJINN同 PROLONETLSTMPPO ReLU
LSTM:
3-layer 8x8 – LSTM(8x8) – 8x4MLPPPO ReLU
MLP:
3-layer 8x8 – 8x8 – 8x4Heuristic(规则)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y9EycMoI-1627308462432)(E:文档TyporaEncoding Human Domain Knowledge to Warm Start Reinforcement Learningimagesclip_image013.png)]](https://img-blog.csdnimg.cn/d10630ce7f334585ba51e6261b415675.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2F6ZXllYXpleWU=,size_16,color_FFFFFF,t_70)
4.1.3 FindAndDefeatZerglings
PPO RMSProp γ=0.99 lr=0.001 parallels=4 batch_size=4 time_steps=50
PROLONET:
α = 1 α=1 α=1 ε = 0.19 ε=0.19 ε=0.19 决策节点10,叶子节点11Random PROLONET强化参数:
PPO RMSProp γ=0.99 lr=0.001 parallels=4 batch_size=4 time_steps=50
LOKI强化参数:
PPO RMSProp γ=0.99 lr=0.001 parallels=4 batch_size=4 time_steps=50
模仿次数:N=500DJJINN同 PROLONETLSTMPPO ReLU
LSTM:
7-layer 37x37 – LSTM(37x37) – 37x37 – 37x37 – 37x37 – 37x37– 37x10MLPPPO ReLU
MLP:
7-layer 37x37 – 37x37 – 37x37 – 37x37 – 37x37 – 37x37 – 37x10Heuristic(规则)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VvJ71NgL-1627308462432)(E:文档TyporaEncoding Human Domain Knowledge to Warm Start Reinforcement Learningimagesclip_image014.png)]](https://img-blog.csdnimg.cn/ae7814eaf3474fd6bd9a02dc998d9778.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2F6ZXllYXpleWU=,size_16,color_FFFFFF,t_70)
4.1.4 SC2LE
等待单位数:如上所述,但用于当前正在生产中且还不存在的单元。
敌方单位数:112x1向量,其中每个索引对应于一种单位类型,值对应于这些类型中有多少是可见的。
玩家状态:9x1向量,玩家状态信息,包括矿物,瓦斯,供应等。动作空间如果考虑到每个单位动作数量可以达到数千个。 简单地将动作抽象为44个可用的动作:包括35个建筑和单位生产命令,4个研究命令,5个攻击、防御、收获资源、侦察和什么都不做的命令。
PPO RMSProp γ=0.99 lr=0.0001 parallels=4 batch_size=4 time_steps=4 episodes
PROLONET:
α = 1 α=1 α=1 ε = 0.19 ε=0.19 ε=0.19 决策节点9,叶子节点10Random PROLONET强化参数:
PPO RMSProp γ=0.99 lr=0.0001 parallels=4 batch_size=4 time_steps=4 episodesLOKI强化参数:
PPO RMSProp γ=0.99 lr=0.0001 parallels=4 batch_size=4 time_steps=4 episodes
模仿次数:N=1000DJJINN同 PROLONETLSTMLSTM:
7-layer 37x37 – LSTM(37x37) – 37x37 – 37x37 – 37x37 – 37x37– 37x10MLPPPO ReLU
MLP:
7-layer 193x193 – 193x193 – 193x193 – 193x193 – 193x193 –193x193 – 193x44Heuristic(规则)
4.2实验结果
cart pole、lunar lander和FindAndDefeatZerglings的架构比较。随着领域复杂性的增加,智能初始化变得越来越重要。

为了评估动态生长和智能初始化的影响,我们进行了消融研究,并将这些实验的结果包括在表1。对于每个N错误智能体,权重、比较器和叶子根据N随机负,每个类别最大为2N。

在《星际争霸2》的AI游戏中获胜率“All Others”包括4.1节中的所有其他智能体模型。

注意最后的策略并不是原始政策的翻版;相反,在整个训练过程中,它们会改变和偏离原来的内容。在下面的图中,比较了检查点模型和原始初始化。x轴对应的是检查点在实验中的距离,y轴对应的是初始化和检查点之间的平均均方误差。由于权重向量、比较器值和叶权值的均方误差可能存在显著差异,因此在y轴上使用对数尺度,以便无论原始值如何,都能清楚地看到趋势。注意,在每25%的训练或agent按照OpenAl Gym标准“解决”了域(推车杆500,月球登陆器200+)后进行检查点,这说明推车杆域的检查点密度更大。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AC2Wq8Tf-1627308462434)(E:文档TyporaEncoding Human Domain Knowledge to Warm Start Reinforcement Learningimagesclip_image016.png.png)]](https://img-blog.csdnimg.cn/25844d89327c470ba0bd6401e75a5fe2.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2F6ZXllYXpleWU=,size_16,color_FFFFFF,t_70#pic_center)
5.创新点在哪里
- 提出一种在可训练的RL框架中捕获人类领域的专业知识的方法PROLoNETS。
- 我们将动态知识增长引入到PROLoNETS中,随着时间的推移,使其具有更强的表达能力,超过最初的初始化,并在月球着陆器领域产生两倍的平均回报。
6.有值得阅读的相关文献吗
LOKI:Cheng, C.-A.; Yan, X.; Wagener, N.; and Boots, B. 2018.Fast Policy Learning through Imitation and Reinforcement.arXiv preprint arXiv:1805.10413 .
DJINN:Humbird, K. D.; Peterson, J. L.; and McClarren, R. G. 2018.Deep Neural Network Initialization With Decision Trees.IEEE transactions on neural networks and learning systems .
7.综合评价又如何?
文章提出了一种新的DRL代理体系结构PROLONETS,它允许智能体的智能初始化。PROLONETS赋予智能体在必要时增长网络容量的能力。PROLONETS允许普通用户初始化,并通过人工指令和RL的混合实现了高性能的策略。首先,该方法直接利用现有专家知识,优于在传统架构上的模仿和强化学习,更像人类学习方式。其次,智能初始化允许深度RL智能体在对随机初始化智能体来说过于复杂的环境中探索和学习,为Fast reinforcement learning提供了一条可用之路。
标签:
相关文章
-
无相关信息