Spring高手之路4——深度解析Spring内置作用域及其在实践中的应用
文章目录
1. Spring的内置作用域
我们来看看Spring内置的作用域类型。在5.x版本中,Spring内置了六种作用域:
我们需要重点学习两种作用域:singleton和prototype。在大多数情况下singleton和prototype这两种作用域已经足够满足需求。
2. singleton作用域
2.1 singleton作用域的定义和用途
Singleton是Spring的默认作用域。在这个作用域中,Spring容器只会创建一个实例,所有对该bean的请求都将返回这个唯一的实例。
例如,我们定义一个名为Plaything的类,并将其作为一个bean:
@Component
public class Plaything {public Plaything() {System.out.println("Plaything constructor run ...");}
}
在这个例子中,Plaything是一个singleton作用域的bean。无论我们在应用中的哪个地方请求这个bean,Spring都会返回同一个Plaything实例。
下面的例子展示了如何创建一个单实例的Bean:
package com.example.demo.bean;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;@Component
public class Kid {private Plaything plaything;@Autowiredpublic void setPlaything(Plaything plaything) {this.plaything = plaything;}public Plaything getPlaything() {return plaything;}
}
package com.example.demo.bean;import org.springframework.stereotype.Component;@Component
public class Plaything {public Plaything() {System.out.println("Plaything constructor run ...");}
} 这里可以在Plaything类加上@Scope(BeanDefinition.SCOPE_SINGLETON),但是因为是默认作用域是Singleton,所以没必要加。
package com.example.demo.configuration;import com.example.demo.bean.Kid;
import com.example.demo.bean.Plaything;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class BeanScopeConfiguration {@Beanpublic Kid kid1(Plaything plaything1) {Kid kid = new Kid();kid.setPlaything(plaything1);return kid;}@Beanpublic Kid kid2(Plaything plaything2) {Kid kid = new Kid();kid.setPlaything(plaything2);return kid;}
}package com.example.demo.application;import com.example.demo.bean.Kid;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.context.annotation.ComponentScan;@SpringBootApplication
@ComponentScan("com.example")
public class DemoApplication {public static void main(String[] args) {ApplicationContext context = new AnnotationConfigApplicationContext(DemoApplication.class);context.getBeansOfType(Kid.class).forEach((name, kid) -> {System.out.println(name + " : " + kid.getPlaything());});}} 在Spring IoC容器的工作中,扫描过程只会创建bean的定义,真正的bean实例是在需要注入或者通过getBean方法获取时才会创建。这个过程被称为bean的初始化。
这里运行 ctx.getBeansOfType(Kid.class).forEach((name, kid) -> System.out.println(name + " : " + kid.getPlaything())); 时,Spring IoC容器会查找所有的Kid类型的bean定义,然后为每一个找到的bean定义创建实例(如果这个bean定义还没有对应的实例),并注入相应的依赖。
运行结果:
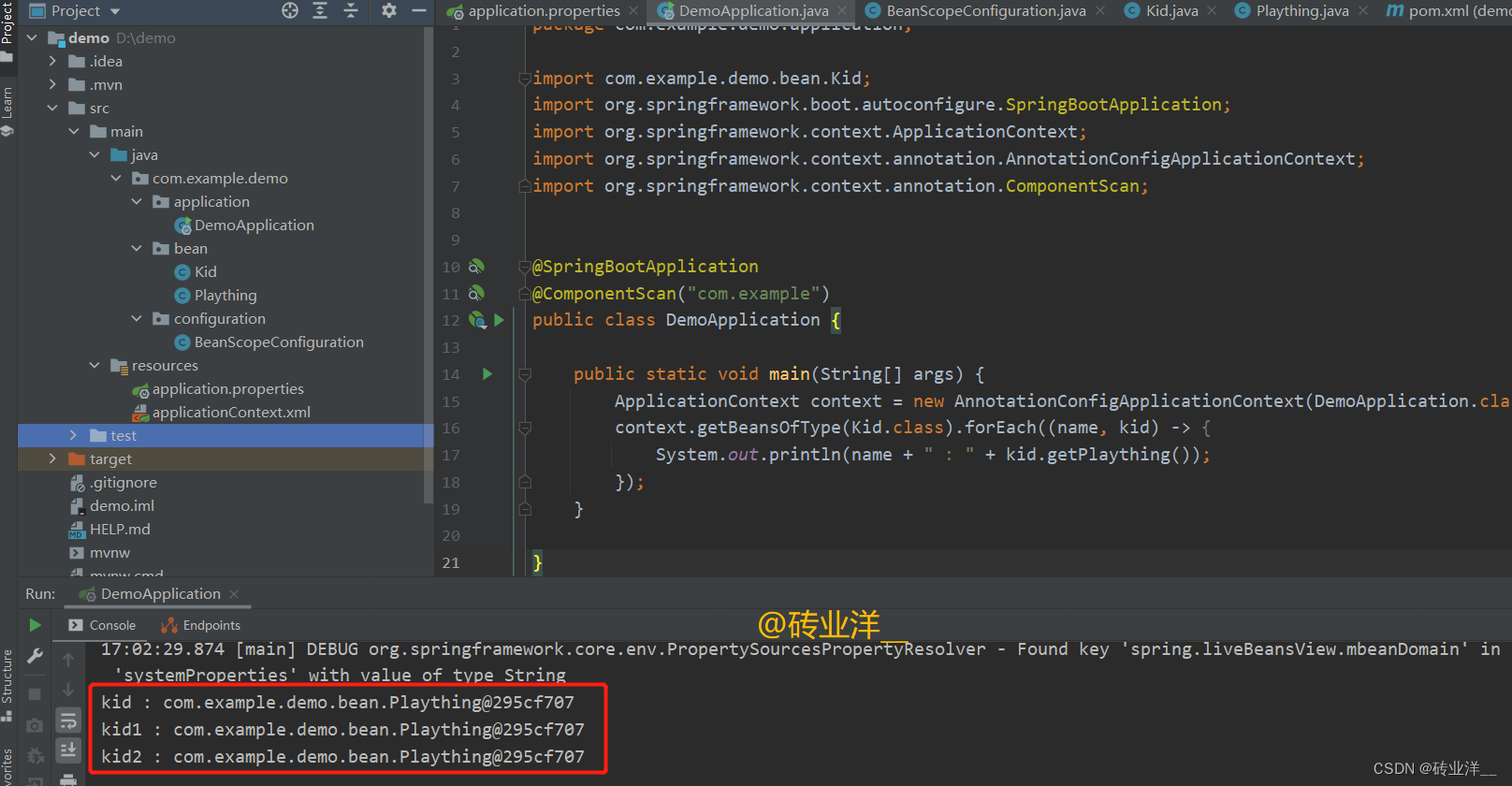
三个 Kid 的 Plaything bean是相同的,说明默认情况下 Plaything 是一个单例bean,整个Spring应用中只有一个 Plaything bean被创建。
为什么会有3个kid?
-
Kid: 这个是通过在
Kid类上标注的@Component注解自动创建的。Spring在扫描时发现这个注解,就会自动在IOC容器中注册这个bean。这个Bean的名字默认是将类名的首字母小写kid。 -
kid1: 在
BeanScopeConfiguration中定义,通过kid1(Plaything plaything1)方法创建,并且注入了plaything1。 -
kid2: 在
BeanScopeConfiguration中定义,通过kid2(Plaything plaything2)方法创建,并且注入了plaything2。
2.2 singleton作用域线程安全问题
需要注意的是,虽然singleton Bean只会有一个实例,但Spring并不会解决其线程安全问题,开发者需要根据实际场景自行处理。
我们通过一个代码示例来说明在多线程环境中出现singleton Bean的线程安全问题。
首先,我们创建一个名为Counter的singleton Bean,这个Bean有一个count变量,提供increment方法来增加count的值:
package com.example.demo.bean;import org.springframework.stereotype.Component;@Component
public class Counter {private int count = 0;public int increment() {return ++count;}
}
然后,我们创建一个名为CounterService的singleton Bean,这个Bean依赖于Counter,在increaseCount方法中,我们调用counter.increment方法:
package com.example.demo.service;import com.example.demo.bean.Counter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;@Service
public class CounterService {@Autowiredprivate final Counter counter;public void increaseCount() {counter.increment();}
}
我们在多线程环境中调用counterService.increaseCount方法时,就可能出现线程安全问题。因为counter.increment方法并非线程安全,多个线程同时调用此方法可能会导致count值出现预期外的结果。
要解决这个问题,我们需要使counter.increment方法线程安全。
这里可以使用原子变量,在Counter类中,我们可以使用AtomicInteger来代替int类型的count,因为AtomicInteger类中的方法是线程安全的,且其性能通常优于synchronized关键字。
package com.example.demo.bean;import org.springframework.stereotype.Component;import java.util.concurrent.atomic.AtomicInteger;@Component
public class Counter {private AtomicInteger count = new AtomicInteger(0);public int increment() {return count.incrementAndGet();}
}
尽管优化后已经使Counter类线程安全,但在设计Bean时,我们应该尽可能地减少可变状态。这是因为可变状态使得并发编程变得复杂,而无状态的Bean通常更容易理解和测试。
什么是无状态的Bean呢? 如果一个Bean不持有任何状态信息,也就是说,同样的输入总是会得到同样的输出,那么这个Bean就是无状态的。反之,则是有状态的Bean。
3. prototype作用域
3.1 prototype作用域的定义和用途
在prototype作用域中,Spring容器会为每个请求创建一个新的bean实例。
例如,我们定义一个名为Plaything的类,并将其作用域设置为prototype:
package com.example.demo.bean;import org.springframework.beans.factory.config.BeanDefinition;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;@Component
@Scope(BeanDefinition.SCOPE_PROTOTYPE)
public class Plaything {public Plaything() {System.out.println("Plaything constructor run ...");}
}
在这个例子中,Plaything是一个prototype作用域的bean。每次我们请求这个bean,Spring都会创建一个新的Plaything实例。
我们只需要修改上面的Plaything类,其他的类不用动。
打印结果:
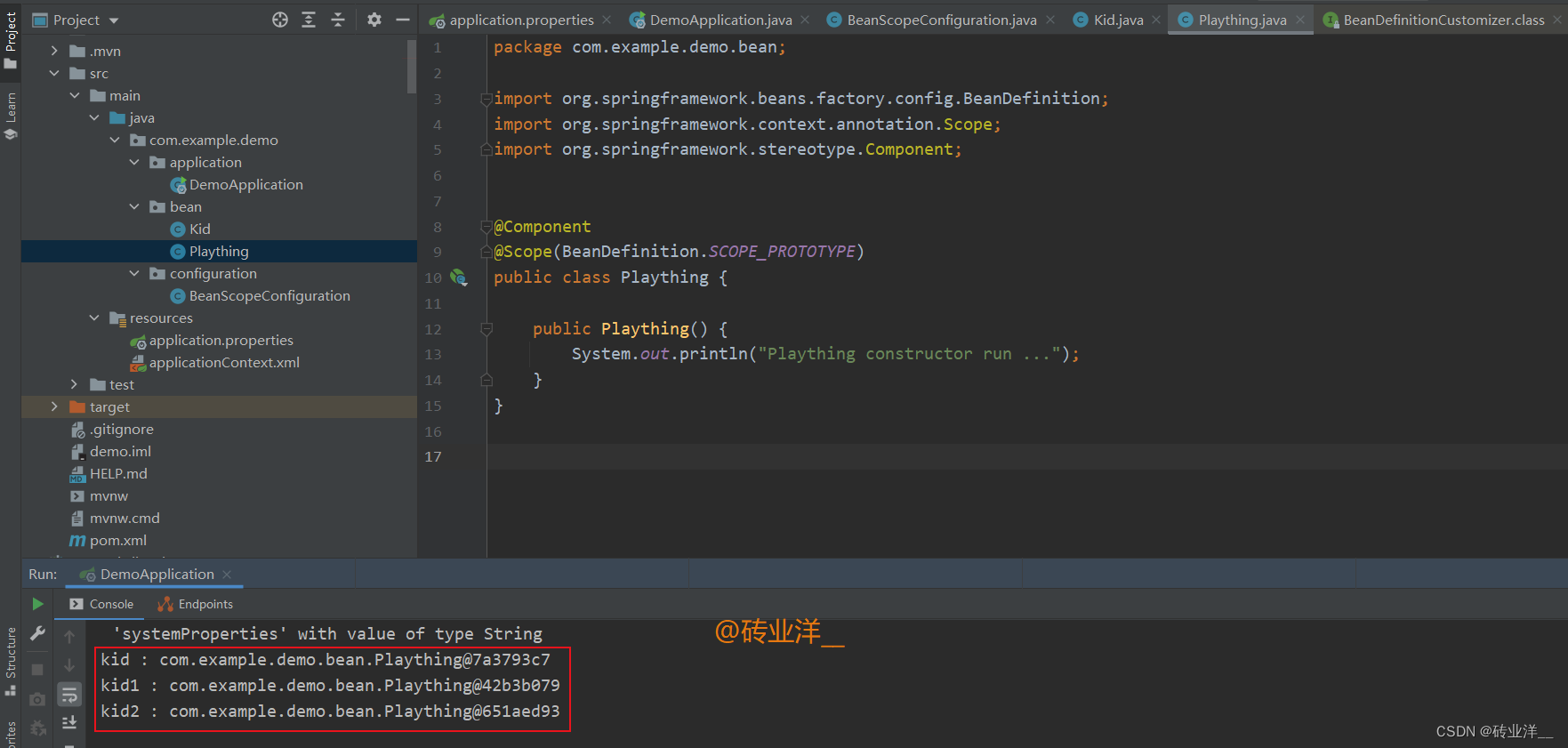
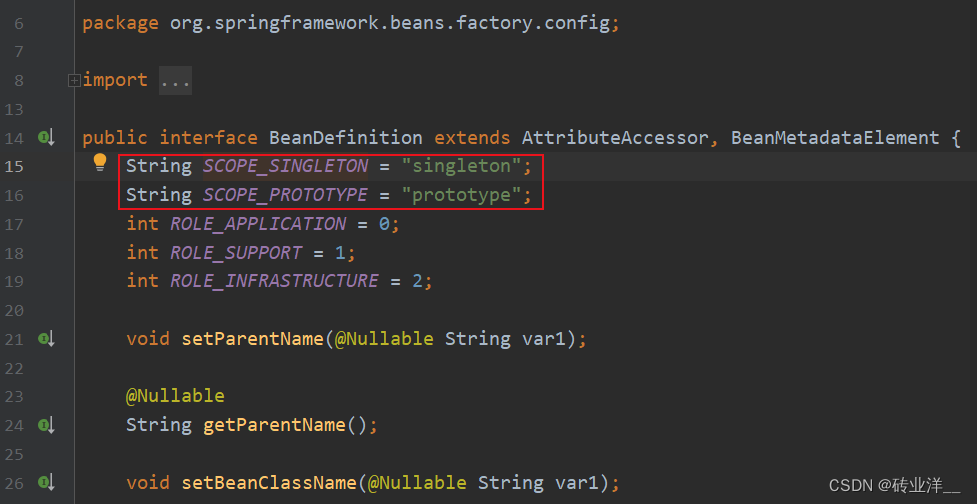
这个@Scope(BeanDefinition.SCOPE_PROTOTYPE)可以写成@Scope("prototype"),按照规范,还是利用已有的常量比较好。
3.2 prototype作用域在开发中的例子
以我个人来说,我在excel多线程上传的时候用到过这个,当时是EasyExcel框架,我给一部分关键代码展示一下如何在Spring中使用prototype作用域来处理多线程环境下的任务(实际业务会更复杂),大家可以对比,如果用prototype作用域和使用new对象的形式在实际开发中有什么区别。
使用prototype作用域的例子
@Resource
private ApplicationContext context;@PostMapping("/user/upload")
public ResultModel upload(@RequestParam("multipartFile") MultipartFile multipartFile) {......ExecutorService es = new ThreadPoolExceutor(10, 16, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(2000), new ThreadPoolExecutor.CallerRunPolicy());......EasyExcel.read(multipartFile.getInputStream(), UserDataUploadVO.class, new PageReadListener(dataList ->{......// 多线程处理上传excel数据,重点只看这一句话Future future = es.submit(context.getBean(AsyncUploadHandler.class, user, dataList, errorCount));......})).sheet().doRead();......
}
有人可能会问这里为什么使用context.getBean,而不是@Resource或@Autowired注解,@Resource或@Autowired注解只会在注入时创建一个新的实例,这里并不会反复注入。ApplicationContext.getBean()方法是在每次调用时解析的,所以它会在每次调用时创建一个新的AsyncUploadHandler实例。
AsyncUploadHandler.java
@Component
@Scope(BeanDefinition.SCOPE_PROTOTYPE)
public class AsyncUploadHandler implements Runnable {private User user;private List dataList;private AtomicInteger errorCount;@Resourceprivate RedisService redisService;......@Resourceprivate CompanyManagementMapper companyManagementMapper;public AsyncUploadHandler(user, List dataList, AtomicInteger errorCount) {this.user = user;this.dataList = dataList;this.errorCount = errorCount;}@Overridepublic void run() {......}......
}
AsyncUploadHandler类是一个prototype作用域的bean,它被用来处理上传的Excel数据。由于并发上传的每个任务可能需要处理不同的数据,并且可能需要在不同的用户上下文中执行,因此每个任务都需要有自己的AsyncUploadHandler bean。这就是为什么需要将AsyncUploadHandler定义为prototype作用域的原因。
由于AsyncUploadHandler是由Spring管理的,我们可以直接使用@Resource注解来注入其他的bean,例如RedisService和CompanyManagementMapper。
如果用单例作用域的AsyncUploadHandler bean行不行?
如果AsyncUploadHandler 对象被定义为一个单例作用域的Spring Bean,那么所有的线程都会共享同一个AsyncUploadHandler 对象。这可能会导致线程安全问题,因为多个线程同时修改同一个对象的状态可能会导致数据不一致,这里我们需要的是每个用户的数据都要上传校验处理等逻辑(用户数据在dataList里面),如果是单例AsyncUploadHandler,AsyncUploadHandler对象里面的dataList属性会因其他线程的影响而导致被修改。
把AsyncUploadHandler交给Spring容器管理,里面依赖的容器对象可以直接用@Resource注解注入。如果采用new出来的对象,那么这些对象只能从外面注入好了再传入进去。
不使用prototype作用域改用new对象的例子
@PostMapping("/user/upload")
public ResultModel upload(@RequestParam("multipartFile") MultipartFile multipartFile) {......ExecutorService es = new ThreadPoolExceutor(10, 16, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(2000), new ThreadPoolExecutor.CallerRunPolicy());......EasyExcel.read(multipartFile.getInputStream(), UserDataUploadVO.class, new PageReadListener(dataList ->{......// 多线程处理上传excel数据Future future = es.submit(new AsyncUploadHandler(user, dataList, errorCount, redisService, companyManagementMapper));......})).sheet().doRead();......
}
AsyncUploadHandler.java
public class AsyncUploadHandler implements Runnable {private User user;private List dataList;private AtomicInteger errorCount;private RedisService redisService;private CompanyManagementMapper companyManagementMapper;......public AsyncUploadHandler(user, List dataList, AtomicInteger errorCount, RedisService redisService, CompanyManagementMapper companyManagementMapper) {this.user = user;this.dataList = dataList;this.errorCount = errorCount;this.redisService = redisService;this.companyManagementMapper = companyManagementMapper;}@Overridepublic void run() {......}......
}
如果直接新建AsyncUploadHandler对象,则需要手动传入所有的依赖,这会使代码变得更复杂更难以管理,而且还需要手动管理AsyncUploadHandler的生命周期。
3.3 prototype作用域在bean之间相互依赖时存在的问题
在后续写文章时,评论区有提问:“如果Bean A依赖Bean B,那如果在配置类中先定义Bean B再定义Bean A,会不会有问题?还是说Spring会自动处理这种依赖关系?”
这个问题我发现在原型作用域这个点还需要再补充讲解一下:
这种情况在没有相互依赖的情况下不会有问题,Spring会在先解析配置类和@Bean方法,获得所有Bean的依赖信息,之后Spring根据依赖关系决定Bean的实例化顺序,而不管配置类中定义的顺序。
如果A依赖B,B依赖A形成循环依赖,对于单例Bean,Spring通过三级缓存机制来解决。对于原型Bean 的循环依赖无法解决,会抛出BeanCurrentlyInCreationException异常,原因是原型Bean每次都会创建新实例,Spring无法管理其完整生命周期。
注意:Spring解析配置类和@Bean方法是在BeanDefinitionReader进行的,这是 refresh 过程的一个步骤。
4. request作用域(了解)
request作用域:Bean在一个HTTP请求内有效。当请求开始时,Spring容器会为每个新的HTTP请求创建一个新的Bean实例,这个Bean在当前HTTP请求内是有效的,请求结束后,Bean就会被销毁。如果在同一个请求中多次获取该Bean,就会得到同一个实例,但是在不同的请求中获取的实例将会不同。
@Component
@Scope(value = WebApplicationContext.SCOPE_REQUEST, proxyMode = ScopedProxyMode.TARGET_CLASS)
public class RequestScopedBean {// 在一次Http请求内共享的数据private String requestData;public void setRequestData(String requestData) {this.requestData = requestData;}public String getRequestData() {return this.requestData;}
}
上述Bean在一个HTTP请求的生命周期内是一个单例,每个新的HTTP请求都会创建一个新的Bean实例。
5. session作用域(了解)
session作用域:Bean是在同一个HTTP会话(Session)中是单例的。也就是说,从用户登录开始,到用户退出登录(或者Session超时)结束,这个过程中,不管用户进行了多少次HTTP请求,只要是在同一个会话中,都会使用同一个Bean实例。
@Component
@Scope(value = WebApplicationContext.SCOPE_SESSION, proxyMode = ScopedProxyMode.TARGET_CLASS)
public class SessionScopedBean {// 在一个Http会话内共享的数据private String sessionData;public void setSessionData(String sessionData) {this.sessionData = sessionData;}public String getSessionData() {return this.sessionData;}
}
这样的设计对于存储和管理会话级别的数据非常有用,例如用户的登录信息、购物车信息等。因为它们是在同一个会话中保持一致的,所以使用session作用域的Bean可以很好地解决这个问题。
但是实际开发中没人这么干,会话id都会存在数据库,根据会话id就能在各种表中获取数据,避免频繁查库也是把关键信息序列化后存在Redis。
6. application作用域(了解)
application作用域:在整个Web应用的生命周期内,Spring容器只会创建一个Bean实例。这个Bean在Web应用的生命周期内都是有效的,当Web应用停止后,Bean就会被销毁。
@Component
@Scope(value = WebApplicationContext.SCOPE_APPLICATION, proxyMode = ScopedProxyMode.TARGET_CLASS)
public class ApplicationScopedBean {// 在整个Web应用的生命周期内共享的数据private String applicationData;public void setApplicationData(String applicationData) {this.applicationData = applicationData;}public String getApplicationData() {return this.applicationData;}
}
如果在一个application作用域的Bean上调用setter方法,那么这个变更将对所有用户和会话可见。后续对这个Bean的所有调用(包括getter和setter)都将影响到同一个Bean实例,后面的调用会覆盖前面的状态。
7. websocket作用域(了解)
websocket作用域:Bean 在每一个新的 WebSocket 会话中都会被创建一次,就像 session 作用域的 Bean 在每一个 HTTP 会话中都会被创建一次一样。这个Bean在整个WebSocket会话内都是有效的,当WebSocket会话结束后,Bean就会被销毁。
@Component
@Scope(value = "websocket", proxyMode = ScopedProxyMode.TARGET_CLASS)
public class WebSocketScopedBean {// 在一个WebSocket会话内共享的数据private String socketData;public void setSocketData(String socketData) {this.socketData = socketData;}public String getSocketData() {return this.socketData;}
}
上述Bean在一个WebSocket会话的生命周期内是一个单例,每个新的WebSocket会话都会创建一个新的Bean实例。
这个作用域需要Spring Websocket模块支持,并且应用需要配置为使用websocket。
欢迎一键三连~
有问题请留言,大家一起探讨学习
----------------------Talk is cheap, show me the code-----------------------
标签:
相关文章
-
无相关信息