XGBoost Algorithm
注:下有视频讲解,可供参考
演变过程
1. CART

2. 集成学习
集成学习(Ensemble Learning)通过构建并结合多个学习器来完成学习任务。 根据基学习器的生成方式,可以分为两大类:Bagging和Boosting。
Bagging Bagging
每次从原始数据集中有放回的随机抽样n个样本形成自助训练集,重复S次后得到S个新的训练集。对每个自助训练集应用弱分类器,这样就得到了S个弱分类器。最后将预测数据放在这S个弱分类器上计算,计算结果采用投票方式(分类问题)和简单求平均(回归问题)即可。
◆ 代表方法:RF随机森林
Boosting Boosting
先从初始训练集训练出一个基学习器;再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注;然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值T;最终将这T个基学习器进行加权结合。
◆ 代表方法:Adaboost、GBDT、XGBoost
3. 提升树

提升树算法(回归问题)
输入:训练数据集![]() ;
;
输出:提升树![]() 。
。
(1)初始化![]() 。
。
(2)对m=1,2,…,M。
(a)计算残差:
![]()
(b)拟合残差![]() 学习一个回归树,得到
学习一个回归树,得到![]() 。
。
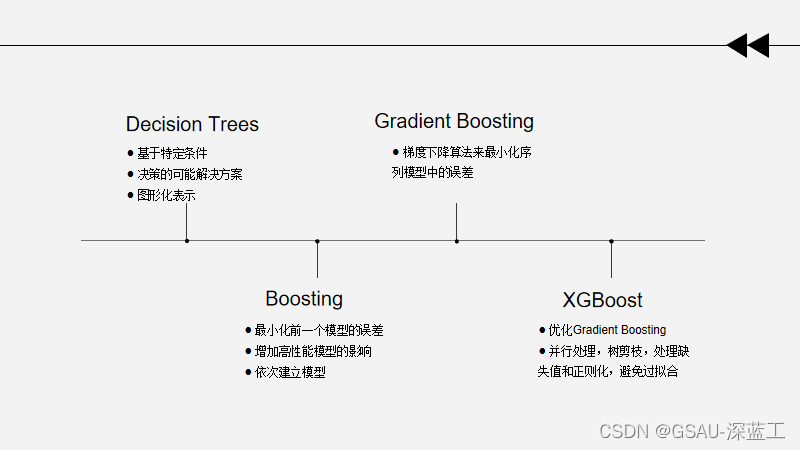
(c)更新
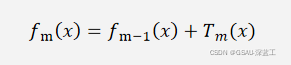
(3)得到回归问题提升树
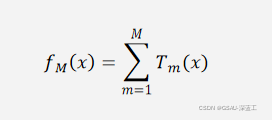
注:◆ 残差是真实值与预测值的差
◆ 加法模型与前向分步算法实现训练
4. GBDT
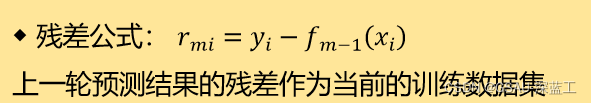
Boosting Tree的残差: 残差是真实值与预测值的差。
GBDT的残差: 用负梯度近似模拟残差。 损失函数是指数损失、平方损失,每一步容易优化。 一般损失函数,每一步优化并不那么容易,所以用负梯度近似逼近。



GBDT优缺点
GBDT的性能在RF的基础上又有一步提升,因此其优点也很明显,
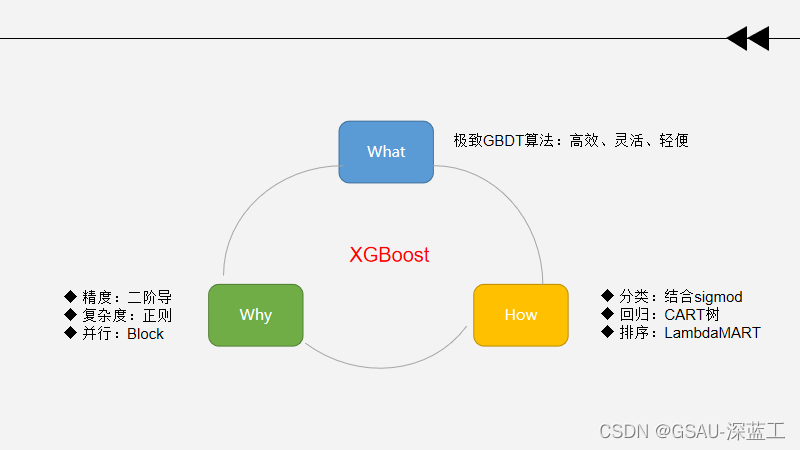
5. XGBoost
XGBoost(eXtreme Gradient Boosting)极致梯度提升,是基于GBDT的一种算法。 XGBoost的基本思想和GBDT相同,但XGBoost进行许多优化,比如:
1.利用二阶公式泰勒展开 :优化损失函数,提高计算精确度。
2. 利用正则项: 简化模型,避免过拟合。
3. 采用Blocks存储结构: 可以并行计算等。
XGBoost目标函数推导、结点分裂方法见文档:https://kdocs.cn/l/cvO0imhAFNzF
XGBboost优缺点
XGBoost VS GBDT
分享视频:
分享人:丁海萌
分享时间:2022/4/26
分享平台:腾讯会议
标签:
相关文章
-
无相关信息