GraphQL-BFF:微服务背景下的前后端数据交互方案
前言
随着多终端、多平台、多业务形态、多技术选型等各方面的发展,前后端的数据交互,日益复杂。
同一份数据,可能以多种不同的形态和结构,在多种场景下被消费。
在理想情况下,这些复杂性可以全部由后端承担。前端只管从后端接口里,拿到已然整合完善的数据。
然而,不管是因为后端的领域模型,还是因为微服务架构。作为前端,我们感受到的是,后端提供的接口,越发不够前端友好。我们必须自行组合多个后端接口,才能获取到完整的数据结构。
面向领域模型的后端需求,跟面向页面呈现的前端需求,出现了不可调和的矛盾。
在这种背景下,本着谁受益谁开发的原则。我们最后选择使用 Node.js 搭建专门服务于前端页面呈现的后端,亦即 Backend-For-Frontend,简称 BFF。
我们面临了很多不同的技术选型,主要围绕在权衡 RESTful API 和 GraphQL。
正如标题所示,我们最终选用的是 GraphQL as BFF。
本文将介绍我们对 GraphQL 所作的考察、探索、权衡、技术选型与设计等多方面的内容,希望能给大家带来一些启发。
一、GraphQL 模式出现的必然性
面向前端页面的数据聚合层,其接口很容易在迭代过程中,变得愈加复杂;最终发展成一个超级接口。
它有很多调用方,各种不同的调用场景,甚至多个不同版本的接口并存,同时提供数据服务。
所有这些复杂性,都会反映到接口参数上。
接口调用的场景越多,它对接口参数结构的表达能力,要求越高。如果只有一个 boolean 类型的参数,只能满足 true | false 两种场景罢了。
以产品详情接口为例,一种很自然的请求参数结构如下:
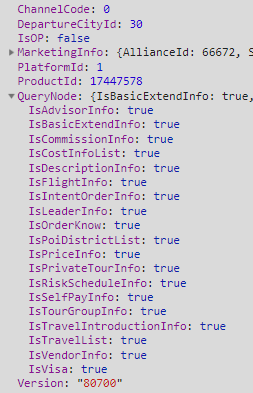
里面包含 ChannelCode 渠道信息,IsOp 身份信息,MarketingInfo 营销相关的信息,PlatformId 平台信息,QueryNode 查询的节点信息,以及 Version 版本信息。最核心的参数 ProductId,被大量场景相关的参数所围绕。
审视一下 QueryNode 参数,很容易可以发现,它正是 GraphQL 的雏形。只不过它用的是更复杂的 JSON 来描述查询字段,而 GraphQL 用更简洁的查询语句,完成同样的目的。
并且,QueryNode 参数,只支持一个层级的字段筛选;而 GraphQL 则支持多层级的筛选。
GraphQL 可以看作是 QueryNode 这种形式的参数设计的专业化。相比用 JSON 来描述查询结果,GraphQL 设计了一个更完整的 DSL,把字段、结构、参数等,都整合到一起。
仿照格林斯潘第十定律:
任何C或Fortran程序复杂到一定程度之后,都会包含一个临时开发的、不合规范的、充满程序错误的、运行速度很慢的、只有一半功能的Common Lisp实现。 https://zh.wikipedia.org/wiki/%E6%A0%BC%E6%9E%97%E6%96%AF%E6%BD%98%E7%AC%AC%E5%8D%81%E5%AE%9A%E5%BE%8B
或许可以说:
任何接口设计复杂到一定程度后,都会包含一个临时开发的、不合规范的、只有一半功能的 GraphQL 实现。
从 SearchParams, FormData 到 JSON,再到 GraphQL 查询语句,我们看到不断有新的数据通讯方式出现,满足不同的场景和复杂度的要求。
站在这个层面上看,GraphQL 模式的出现,有一定的必然性。
二、GraphQL 语言设计中的必然性
作为一个查询相关的 DSL,GraphQL 的语言设计,也不是随意的。
我们可以做一个思想实验。
假设你是一名架构师,你接到一项任务,设计一门前端友好的查询语言。要求:
查询语法跟查询结果相近
能精确查询想要的字段
能合并多个请求到一个查询语句
无接口版本管理问题
代码即文档
我们知道查询结果是 JSON 数据格式。而 JSON 是一个 key-value pair 风格的数据表示,因此可以从结果倒推出查询语句。
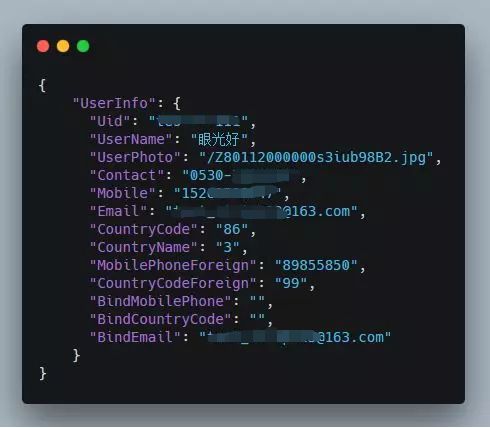
上图是一个查询结果。很显然,它的查询语句不可能包含 value 部分。我们删去 value 后,它变成下面这样。
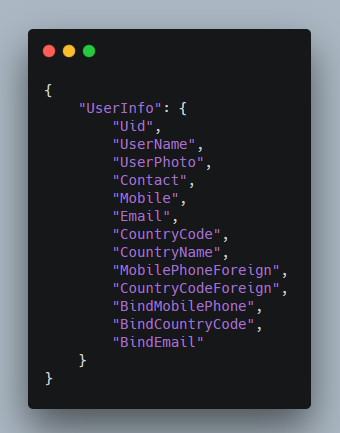
查询语句跟查询结果拥有相同的 key 及其层次结构关系。这是我们想要的。
我们可以再进一步,将冗余的双引号,逗号等部分删掉。
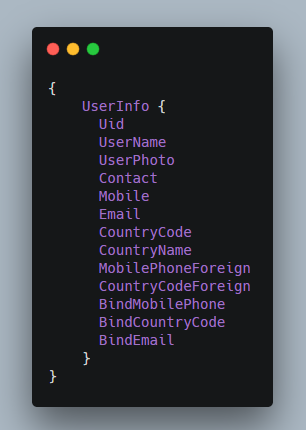
我们得到了一个精简的写法,它已经是一段合法的 GraphQL 查询语句了。
其中的设计思路和过程是如此简单直接,很难想象还有别的方案比目前这个更满足要求。
当然,只有字段和层级,并不足够。符合这种结构的数据太多了,不可能把整个数据库都查询出来。我们还需要设计参数传递的方式,以便能缩小数据范围。
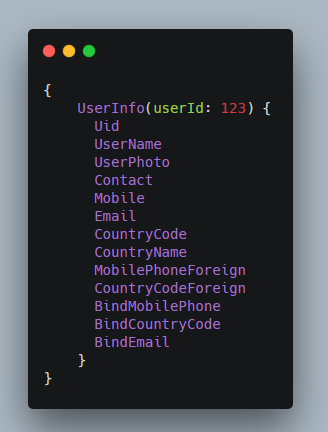
上图是一个自然而然的做法。用括号表示函数调用,里面可以添加参数,可谓经典的设计。
它跟 ES2015 里的 (Method Definitions Shorthand) 也高度相似。如下所示:
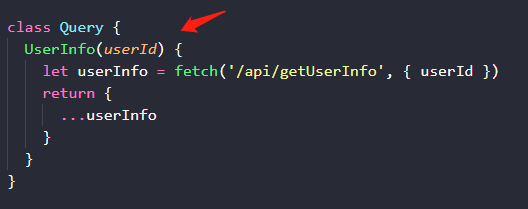
前面演示的 GraphQL 参数写法,参数值用的是字面量 userId: 123。这不是一个特别安全的做法,开发者会在代码里,用拼接字符串的方式将字面量值注入到查询语句,也就给了恶意攻击者注入代码的机会。
我们需要设计一个参数变量语法,明确参数位置和数量。
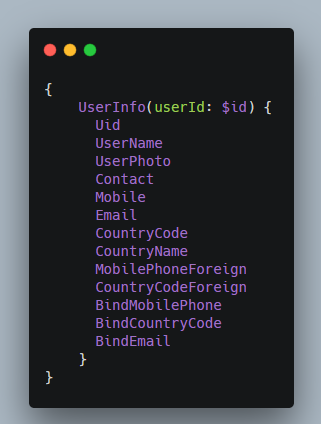
我们可以选用 $xxx 这种常见的标记方法,它被很多语言采用来表示变量。沿用这种风格,可以大大减少开发者的学习成本。
前后端通讯的另一个痛点是,命名。前端经常吐槽后端的字段名过于冗长,或者不知所云,或者拼写错误,或者不符合前端表述习惯。最常见的情况是,后端字段名以大写字母开头,而前端习惯 Class 或者 Component 是大写字母开头,实例和数据,则以小写字母开头。
我们期望有机会进行字段名调整。
别名映射(Alias)语法,正是为了这个目的而出现的。
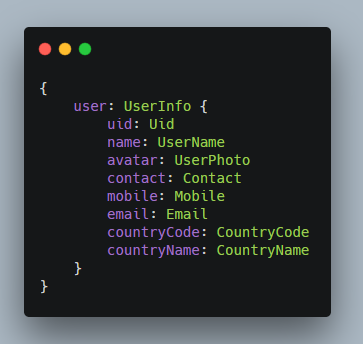
上面这种别名映射的语法,在其它语言里也很常见。如果不这样写,顶多就是变成:
uid as Uid 或者 uid = Uid 这类做法,差别不大。我认为选用冒号更佳,它跟 ES2015 的解构语法很接近。

至此,我们拥有了 key 层级结构,参数传递,变量写法,别名映射等语法,可以编写足够复杂的查询语句了。不过,还有几个小欠缺。
比如对字段的条件表达。假设有两次查询,它们唯一的差别就是,一个有 A 字段,另一个没有 A 字段,其它字段及其结构都是相同的。为了这么小的差别 ,前端难道要编写两个查询语句?
这显然不现实,我们需要设计一个语法描述和解决这个问题。
它就是——指令(Directive)。
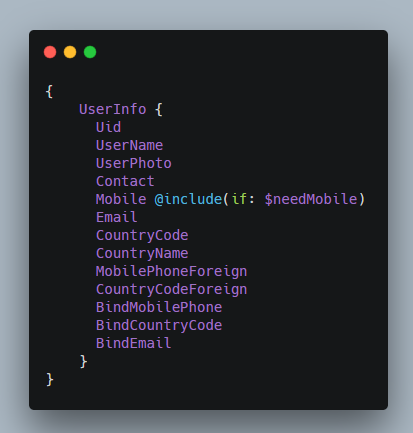
指令,可以对字段做一些额外描述,比如
@include,是否包含该字段;
@skip,是否不包含该字段;
@deprecate,是否废弃该字段;
除了上述默认指令外,我们还可以支持自定义指令等功能。
指令的语法设计,在其它语言里也可以找到借鉴目标。Java,Phthon 以及 ESNext 都用了 @ 符号表示注解、装饰器等特性。
有了指令,我们可以把两个高度相似的查询语句,合并到一起,然后通过条件参数来切换。这是一个不错的做法。不过,指令是跟着单个字段走的,它不能解决多字段的问题。
比如,字段 A 和字段 B,拥有相同的总体结构,仅仅只有 1 个字段名的差异。前端并不想编写一样的 key 值重复多次。
这意味着,我们需要设计一个片段语法(Fragment)。
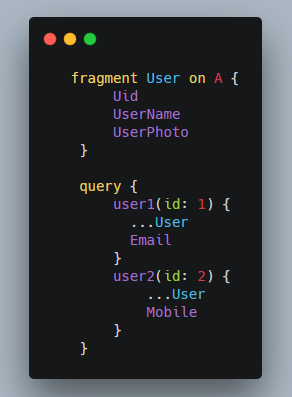
如上所示,用 fragment 声明一个片段,然后用三个点表示将片段在某个对象字段里展开。我们可以只编写一次公共结构,然后轻易地在多个对象字段里复用。
这种设计也是一个经典做法,跟 JavaScript 里的 Spread Properties 很相近。

至此,我们得到了一个相对完整的,对前端友好的查询语言设计。它几乎就是 GraphQL 当前的形态。
如你所见,GraphQL 的查询语言设计,借鉴了主流开发语言里的众多成熟设计。使得任何拥有丰富的编程经验的开发者,很容易上手 GraphQL。
按照同样的要求,重新来一遍,大概率得到跟当前形态高度接近的设计。这是我理解的 GraphQL 语言设计里包含的必然性。
三、GraphQL 的组成与链路
查询语法,是 GraphQL 面向前端,或者说面向数据消费端的部分。
除此之外,GraphQL 还提供了面向后端,或者说面向数据提供方的部分。它就是基于 GraphQL 的 Type System 构建的 Schema。
一个 GraphQL 服务和查询的链路,大致如下:

首先,服务端编写数据类型,构建一个数据结构之间的关联网络。其中 Query 对象是数据消费的入口。所有查询,都是对 Query 对象下的字段的查询。可以把 Query 下的字段,理解为一个个 RESTful API。比如上图中的,Query.post 和 Query.author,相当于 /post 和 /author 接口。
GraphQL Schema 描述了数据的类型与结构,但它只是形状(Shape),它不包含真正的数据。我们需要编写 Resolver 函数,在里面去获取真正的数据。
Resolver 的简单形式如下
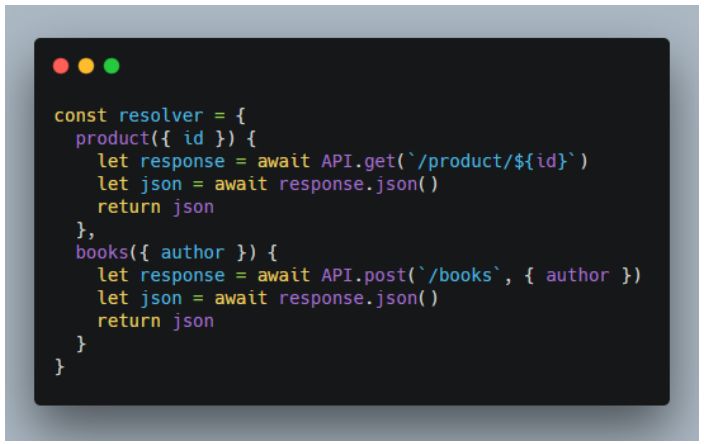
每个 Query 对象下的字段,都有一个取值函数,它能获取到前端传递过来的 query 查询语句里包含的参数,然后以任意方式获取数据。Resolver 函数可以是异步的。
有了 Resolver 和 Schema,我们既定义了数据的形状,也定义了数据的获取方式。可以构建一个完整的 GraphQL 服务。
但它们只是类型定义和函数定义,如果没有调用函数,就不会产生真正的数据交互。
前端传递的 query 查询语句,正是触发 Resolver 调用的源头。
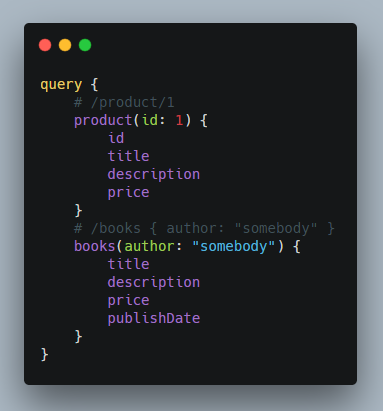
如上所示,我们发起了查询,传递了参数。GraphQL 会解析我们的查询语句,然后跟 Schema 进行数据形状的验证,确保我们查询的结构是存在的,参数是足够的,类型是一致的。任何环节出现问题,都将返回错误信息。
数据形状验证通过后,GraphQL 将会根据 query 语句包含的字段结构,一一触发对应的 Resolver 函数,获取查询结果。也就是说,如果前端没有查询某个字段,就不会触发该字段对应的 Resolver 函数,也就不会产生对数据的获取行为。
此外,如果 Resolver 返回的数据,大于 Schema 里描绘的结构;那么多出来的部分将被忽略,不会传递给前端。这是一个合理的设计。我们可以通过控制 Schema,来控制前端的数据访问权限,防止意外的将用户账号和密码泄露出去。
正是如此,GraphQL 服务能实现按需获取数据,精确传递数据。
四、澄清关于 GraphQL 的几个迷思
有相当多的开发者,对 GraphQL 有各种各样的误解。在这里挑选几个重要的例子,加以澄清,帮助大家更全面的认识 GraphQL。
[4.1] GraphQL 不一定要操作数据库
有一些开发者认为 GraphQL 需要操作数据库,因此实现起来,几乎等于要推翻当前后端的所有架构。这是一个重大误解。
GraphQL 不仅可以不操作数据库,它甚至可以不从其它地方获取数据,而直接写死数据在 Resolver 函数里。查看 graphql.js 的官方文档,我们轻易可以找到案例:
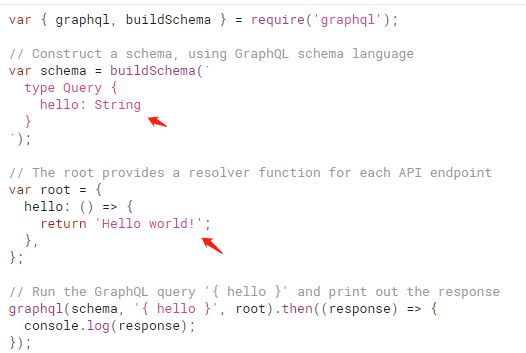
上图定义了一个 schema,只有一个类型为 String 的 hello 字段,它的 resolver 函数里,无视所有参数,直接 return 一个 hello world 字符串。
可以看到,GraphQL 只是关于 schema 和 resolver 的一一对应和调用,它并未对数据的获取方式和来源等做任何假设。
[4.2] GraphQL 跟 RESTful API 不是对立的
在网络上,有相当多的 GraphQL 文章,将它跟 RESTful API 对立起来,仿佛要么全盘 GraphQL,要么全盘 RESTful API。这也是一个重大误解。
GraphQL 和 RESTful API 不仅不对立,还是互相协作的关系。
在前面关于 Resolver 函数的图片中,我们看到,可以在 GraphQL Schema 的 Resolver 函数里,调用 RESTful API 去获取数据。
当然,也可以调用 RPC 或者 ORM 等方式,从别的数据接口或者数据库里获取数据。
因此,实现一个 GraphQL 服务,并不需要挑战当前整个后端体系。它具有高度灵活的适配能力,可以低侵入性的嵌入当前系统中。
[4.3] GraphQL 不一定是一个后端服务
尽管绝大多数 GraphQL,都以 server 的形式存在。 但是,GraphQL 作为一门语言,它并没有限制在后端场景。
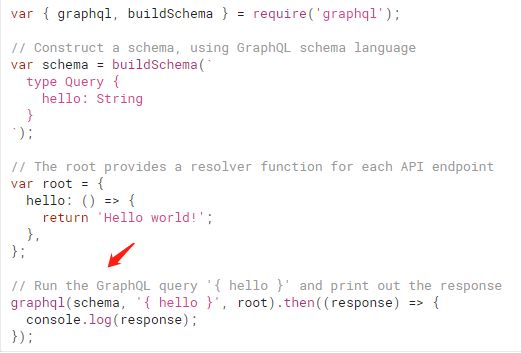
上图还是前面展示过的 graphql.js 的官方文档,最下面一行,就是一个普通的函数调用,它发起了一次 graphql 查询,其 response 结果如下:

这段代码,不只能在 node.js 里运行,在浏览器里也可以运行(可访问:https://codesandbox.io/s/hidden-water-zfq2t 查看运行结果)
因此,我们完全可以将 GraphQL 用在纯前端,去实现 State Management 状态管理。Relay 等框架,即包含了用在前端的 graphql。
[4.4] GraphQL 不一定需要 Schema
这是一个有趣的事实,GraphQL 语言设计里的两个组成部分:
1)数据提供方编写 GraphQL Schema;
2)数据消费方编写 GraphQL Query;
这种组合,是官方提供的最佳实践。但它并不是一个实践意义上的最低配置。
GraphQL Type System 是一个静态的类型系统。我们可以称之为静态类型 GraphQL。此外,社区还有一种动态类型的 GraphQL 实践。
graphql-anywhere: Run a GraphQL query anywhere, without a GraphQL server or a schema. https://github.com/apollographql/apollo-client/tree/master/packages/graphql-anywhere
它跟静态类型的 GraphQL 差别在于,没有了基于 Schema 的数据形状验证阶段,而是直接无脑地根据 query 查询语句里的字段,去触发 Resolver 函数。
它也不管 Resolver 函数返回的数据类型对不对,获取到什么,就是什么。一个字段,不必先定义好,才能被前端消费,它可以动态的计算出来。
在某些场景下,动态类型的 GraphQL 有一定的便利性。不过,它同时丧失了 GraphQL 的部分精髓,这块后面将会详细描述。
值得一提的是,不管是静态类型的 GraphQL 还是动态类型的 GraphQL,都是既可以运行在服务端,也可以运行在前端。
[4.5] GraphQL 不一定返回 JSON 数据格式
这是另一个有趣的事实。最初我们演示了,如何基于 JSON 数据结果,反推出 GraphQL 查询语法的设计。而现在,我们却说 GraphQL 可以不返回 JSON 数据格式。
没错。当一个新事物出现之后,随着它的不断发展,它可以脱离其初衷,衍生出不同的形态。
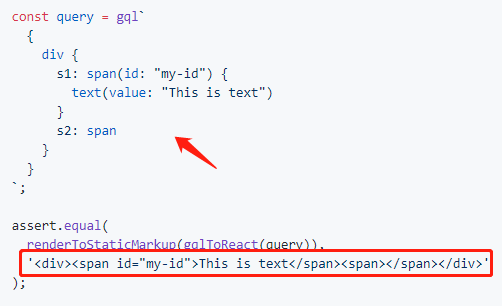
上图还是来自 graphql-anywhere 里的例子。
在这里,它实现了一个 gqlToReact 的 Resolver,可以把一个 graphql 查询转换为 ReactElement 结构。
不只是动态类型的 GraphQL 有这个能力,静态类型的 GraphQL 也有可能实现一样的效果。
不过这种做法,目前仅仅停留在能力演示阶段。其妙用还有待社区去挖掘和探索。
五、GraphQL 的几种使用模式
到目前为止,我们见识到了 GraphQL 的高自由度和灵活性。在搭建 GraphQL Server 时,也可以根据实际需求和场景,采用不同的模式。
[5.1] RESTful-Like 模式
这个模式就是简单粗暴的把 RESTful API 服务,替换成 GraphQL 实现。之前有多少 RESTful 服务,重构后就有多少 GraphQL 服务。它是一个简单的一对一关系。
默认情况下,面向两个 GraphQL 服务发起的查询是两次请求,而不是一次。举个例子:
前端需要产品数据时,从之前调用产品相关的 RESTful API,变成查询产品相关的 GraphQL。不过,需要订单相关的数据时,可能要查询另一个 GraphQL 服务。
有一些公司拿 GraphQL 小试牛刀时,采取了这个做法;将 GraphQL 用在特定服务里。
不过,这种模式难以发挥 GraphQL 合并请求和关联请求的能力。只是起到了按需查询,精确查询字段的作用,价值有限。
因此,他们在实践后,发现收效甚微;认为 GraphQL 不过如此,还不如 RESTful API 架构简单和成熟。
其实这是一种选型上的失误。
[5.2] GraphQL as an API Gateway 模式
在这个模式里,GraphQL 接管了前端的一整块数据查询需求。

前端不再直接调用具体的 RESTful 等接口,而是通过 GraphQL 去间接获取产品、订单、搜索等数据。
在 GraphQL 这个中间层里,我们将各个微服务,按照它们的数据关联,整合成一个基于 GraphQL Schema 的数据关系网络。前端可以通过 GraphQL 查询语句,同时发起对多个微服务的数据的获取、筛选、裁剪等行为。
值得一提的是,作为 API Gateway 的 GraphQL 服务,可以在其 Resolver 内,向前面提到的 RESTful-like 的 GraphQL 发起查询请求。
如此,既避免了前端需要一对多的问题,也解决了 API Gateway GraphQL 需要请求 RESTful 全量数据接口的内部冗余问题。让服务到服务之间的数据调用,也可以做到更精确。
GraphQL 服务是一个对数据消费方友好的模式。而数据消费方,既可以是前端,也可以是其它服务。
当数据消费方是其它服务时,通过 GraphQL 查询语句,彼此之间可以更精确获取数据,避免冗余的数据传输和接口调用。
当数据消费方是前端时,由于前端需要跟多个数据提供方打交道,如果每个数据提供方都是单独的 GraphQL,那并不能得到本质上的改善。此时若有一个 Gateway 角色的 GraphQL,可以真正减少前端调用的复杂度。
[5.2.1] 两类 GraphQL API Gateway 服务
同样是 API Gateway 角色的 GraphQL 服务,在实现方式上也有不同的分类。
1)包含大量真实的数据操作和处理的 GraphQL
2)转发数据请求,聚合数据结果的 GraphQL
第一类,是传统意义上的后端服务;第二类,则是我们今天的重点,GraphQL as BFF。
这两类 GraphQL 服务的要求是不同的,前者可能包含大量 CPU 密集的计算,而后者总体而言主要是 Network I/O 相关的行为。
许多公司并不提倡使用 Node.js 构建第一种服务,不管是构建 RESTful 还是 GraphQL。我们也一样。
因此,后面我们讨论的 GraphQL,如果没有特别声明,都可以理解为上面所说的第二种类型。
[5.3] GraphQL as a Backend Framework
在澄清关于 GraphQL 的迷思时,我们指出,GraphQL 可以不作为 Server。
这意味着,一个包含 GraphQL 实现的 Server,不一定通过 GraphQL 查询语句进行前后端数据交互,它可以继续沿用 RESTful API 风格。
也就是说,我们可以把 GraphQL 当作一个服务端开发框架,然后在 RESTful 的各个接口里,发起 graphql 查询。
不管是前端跟其它后端服务,都不必知道 GraphQL 的存在。前端的调用方式,还是 RESTful API,在 RESTful 服务内部,它自己向自己发起了 GraphQL 查询。
那么,这个模式有什么好处跟价值?
设想一下,你用 RESTful API 风格实现 BFF。由于 PC 端和移动端的场景不同,它们对同一份数据的消费方式差异很大。
在 PC 端,它可以一次请求全量数据。
在移动端,因为它屏幕小,它要分多次去请求数据。首屏一次,非首屏一次,滚动按需加载 N 次,多个 2 级页面里 M 次。
我们要么实现一个超级接口,根据请求参数适配不同场景(即实现一个半吊子的 GraphQL);要么实现多个功能相似,但又不同的 RESTful 接口。
其中的差异太大了,所以很多公司索性就把 BFF 分成,PC-BFF 和 Mobile-BFF 两个 BFF 服务。
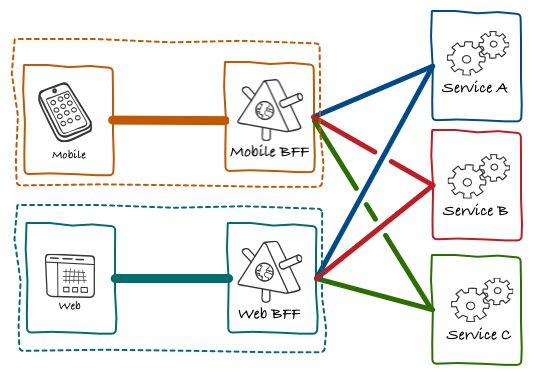
我们可以把 PC-BFF 和 Mobile-BFF 整合成一个 GraphQL-BFF 服务。即便前后端不通过 GraphQL 查询语句进行交互,我们也可以在各个接口里,编写相对简单的查询语句,代替更高成本的接口实现。
也即是说,使用 GraphQL 搭建 BFF,如果出现前后端分工、沟通等方面的矛盾。我们可以将 GraphQL 服务降级为 RESTful 服务,无非就是把需要前端编写的查询语句,写死在后端接口里面罢了。
如果实现的是 RESTful 服务,要转换成 GraphQL 服务,就没有那么简单了。
有了这种优雅降级的能力,我们可以更加放心大胆的推动 GraphQL-BFF 方案。
六、GraphQL 精髓
理解 GraphQL 的精髓所在,可以帮助我们更正确地实践 GraphQL。
首先来想一下,GraphQL 为什么要叫 GraphQL,其中的 Graph 体现在什么地方?
GraphQL 的查询语句,看起来是 JSON 写法的一种简化。而 JSON 是一个 Tree 树形数据结构。为什么不叫 TreeQL,而是 GraphQL 呢?
[6.1] Tree VS Graph
一个重要的前置知识是,什么是 Tree,什么是 Graph,它们有什么关系?
下图是一个 Tree 的结构示意图。
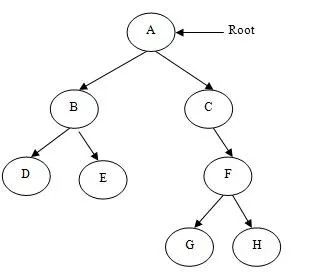
Tree 有且只有一个 Root 节点,并且对于每个非 Root 节点,有且只有一个父节点;它们组成了一个层次结构。其中任意两个节点,有且只有一条连接路径;没有循环,也没有递归引用。
下图是一个 Graph 的结构示意图。
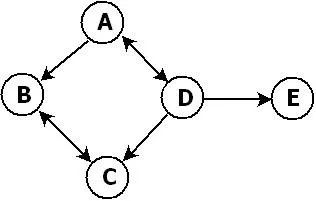
而 Graph 里的节点之间,可能存在不只一种连接路径,可能存在循环,可能存在递归引用,可能没有 Root 节点。它们组成了一个网络结构。
我们可以把 Graph 这种网络结构,通过裁剪连接路径,把它压缩成任意节点只有唯一连接路径的简化形态。如此网络结构退化成层次结构,它变成了 Tree。
也就是说,Graph 是比 Tree 更复杂的数据结构,后者是它的简化形式。拥有 Graph,我们可以按照不同的裁剪方式,衍生出不同的 Tree。而 Tree 里包含的信息,如果不增加其它额外数据,不足以构建足够复杂的 Graph 结构。
[6.2] GraphQL 里的 Graph 结构
在 GraphQL 里,承担构建网络结构的,并非 GraphQL 查询语句,而是基于 GraphQL Type System 构建的 Schema。
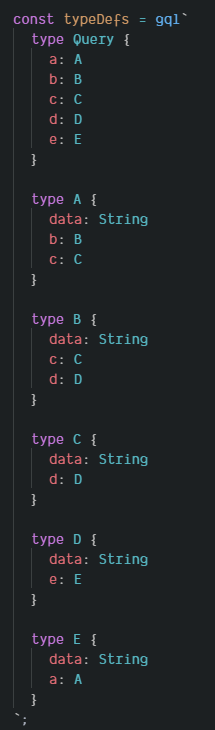
上图是一个 GraphQL Schema,定义了 A, B, C, D 和 E 五种数据类型,它们分别挂载到 入口类型 Query 里的 a, b, c, d 和 e 字段里。
A, B, C, D, E 里面,包含着递归的结构。A 里面包含 B 和 C,B 里面包含 C 和 D,D 里面包含 E,E 里面又包含 A,又回到了 A。
这是一个复杂的关系网络。要构建递归关联,并不需要这么复杂。直接 A 里包含 B,和 B 里包含 A 也行,此处是一个演示。
有了这个基于数据类型的 Graph 关系网络,我们可以实现从 Graph 中派生出 JSON Tree 的能力。

上图是一个 GraphQL 的查询语句,它是一个包含很多 key 的层次结构,亦即一个 Tree。
它从跟节点里取 a 字段,然后向下分层,找到了 e。而 e 节点里也包含一个跟根节点同类型的 a 字段,因此它可以继续向下分层,重来一遍,又到了 e 节点,此时它只取了 data 字段,查询中止。
我编写了一个简单的 Resolver 函数,用来演示查询结果。
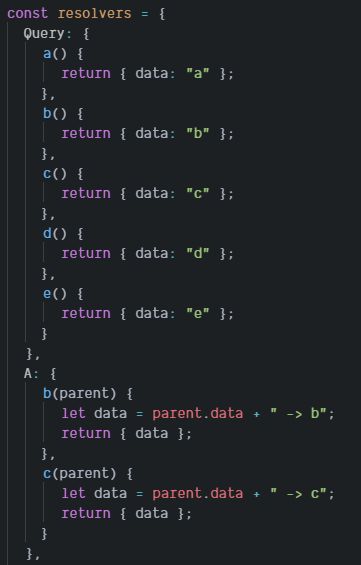
它很简单。Query 里返回跟字段名一样的字母,任何子节点的数据,都是拼接父节点的字母串。如此我们可以从查询结果看出数据流动的层次。
查询结果如下:
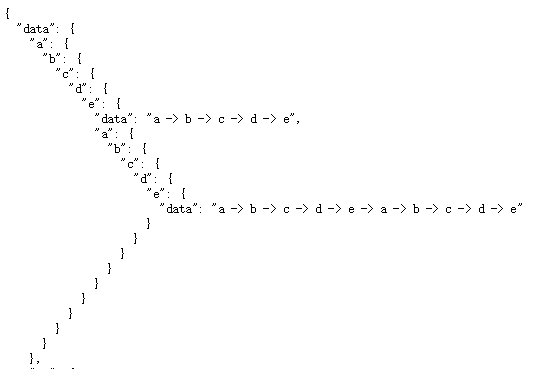
第一个 e 节点的 data 字段里,拿到了父节点里的 data 数据,其父节点的 data 数据又是通过它的父节点里获取的,因此有一个数据链条。
而第二个 e 节点同理,它有两段链条。
只要不编写后续字段,我们可以停留在任意节点的 data 字段里。
也就是说,我们用作为 Tree 的 Query 语句,去裁剪了作为 Graph 的 Schema 数据关联网络,得到了我们想要的 JSON 结构。
通过这个角度,我们可以理解为什么 GraphQL 不允许 Query 语句停留在 Object 类型,一定要明确的写出对象内部的字段,直到所有 Leaf Node 都是 Scalar 类型。
这不仅仅是一个所谓的最佳实践,这也是 Graph 本身的特征。对象节点里,可能通过循环或者递归关系,拓展出无限大的数据结构。Query 语句必须写清楚,才能帮助 GraphQL 去裁剪掉不必要的数据关联路径。
[6.3] Graph 网络结构的实际价值
前面的 A, B, C, D, E 案例,并不能直观的让大家感受到,Graph 网络结构的实际价值。它看起来像一个连线游戏。
放到 Facebook 的社交网络场景下,其必要性和价值就凸显了。
假设我们要一次性获取用户的好友的好友的好友的好友的好友,基于 RESTful API 我们有什么特别好的方法吗?很难说。
而 Graph 这种递归关联的结构,实现这种查询轻而易举。
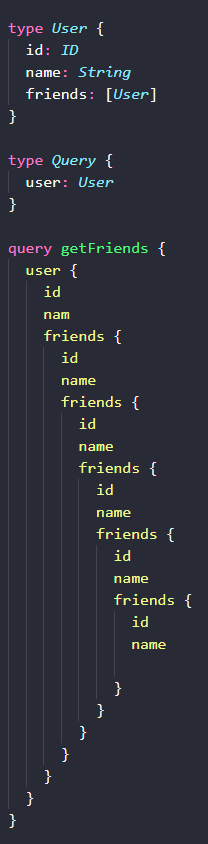
我们定义了一个 User 类型,挂到 Query 入口上的 user 字段里。Use 类型的 friends 字段又是一个 User 类型的列表。这样就构建了一个递归关联。
getFriends 查询语句,可以不断地从任意用户开始,关联其 friends,得到 friends 数组结果。任意一个 friend 也是 User,它也有自己的 friends。查询依据在最外层的 friends 停了下来,它只查询了 id 和 name 字段。
看到这里,另一个经典的关于 GraphQL 的误解出现了:只有像 Facebook,Twitter 这类社交关系网络,才适合 GraphQL,而我们的场景下,GraphQL 并不适用。
其实不然,社交关系网络里使用 GraphQL 特别有效,不意味着其它场景下,GraphQL 不能带来收益。
设想一个电商平台的场景,它有用户、产品和订单这组铁三角,其它库存、价格,优惠券,收藏等先不提。在最简单的场景下,GraphQL 依然可以发挥作用。
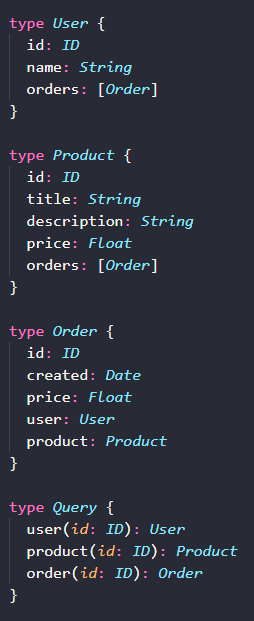
我们构建了 User,Product 和 Order 三个类型,它们彼此之间有字段上的递归关联关系,是一个 Graph 结构。在 Query 入口类型上,分别有 user, product 和 order 三个字段。
据此,我们可以实现从 user, product 和 order 任意维度出发,通过它们的关联关系,实现丰富而灵活的查询。
比如,查看用户的所有订单及其跟订单相关的产品,Query 语句如下:
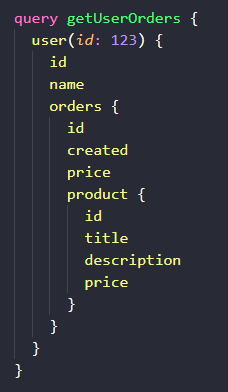
我们查询了 id 为 123 的用户,他的名字和订单列表,对于每个订单,我们获取该订单的创建时间,购买价格和关联产品,对于订单关联的产品,我们获取了产品 id,产品标题,产品描述和产品价格。
当我们的后端人员组织架构是按照领域模型来划分时,用户,产品和订单,通常是 3 个团队,他们各自提供领域相关的接口。通过 GraphQL 我们可以很容易将它们整合到一起。
再比如,查看一个产品下的所有订单及其关联用户,Query 语句如下:
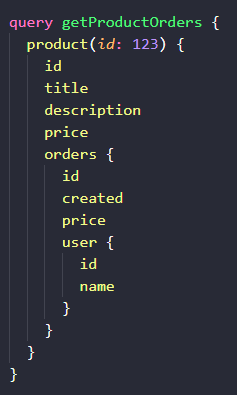
我们查询了 id 为 123 的产品,它的产品标题,产品描述和价格,以及关联的订单。对于每个关联订单,我们查询了订单的创建时间,购买价格以及下订单的用户,对于下订单的用户,我们查询了他的用户 id 和名称。
如你所见,只要构建出了 Graph 结构的数据网络,它不像 Tree 那样有唯一的 Root 节点。从任意入口出发,它都可以通过关联路径,不断的衍生出数据,得到 JSON 结果。
我们不必疲于编写面向产品详情页的接口,面向订单详情页的接口,面向用户信息的接口。我们编写了一个数据关系网络,就足以适配不同的场景。
此处演示的,只是用户,产品和订单这三个资源的关系网络,已经可以看出 GraphQL 的适用性。在实际场景中,我们能搭建出更复杂的数据网络,它具备更强大的数据表达能力,可以给我们的业务带来更多收益。
七、我们的 GraphQL-BFF 实践模式
在掌握上述关于 GraphQL 的纲领知识后,我们来看一下在实践中 ,GraphQL-BFF 的一种实际做法。
首先是技术选型,我们主要采用了如下技术栈。

开发语言选用了 TypeScript,跑在 Node.js v10.x 版本上,服务端框架是 Koa v2.x 版本,使用 apollo-server-koa 模块去运行 GraphQL 服务。
Apollo-GraphQL 是 Node.js 社区里,比较知名和成熟的 GraphQL 框架。做了很多的细节工作,也有一些相对前沿的探索,比如Apollo Federation 架构等。
不过,有两点值得一提:
1)Apollo-GraphQL 属于 GraphQL 社区的一部分,而非 Facebook 官方的 GraphQL 开发团队。Apollo-GraphQL 在官方 GraphQL 的基础上进行了带有他们自身理念特点的封装和设计。像 Apollo Federation 这类目前看来比较激进的方案,即使是 GraphQL 官方的开发人员,对此也持保留态度。
2)Apollo-GraphQL 的重心是前文所说的第一类 API Gateway 角色的 GraphQL 服务,本文探讨的是第二类。因此,Apollo-GraphQL 里有很多功能对我们来说没必要,有一些功能的使用方式,跟我们的场景也不契合。
我们主要使用的是 Apollo-GraphQL 的 graphql-tools 和 apollo-server-koa 两个模块,并在此基础上,进行了符合我们场景的设计和改编。
[7.1] 我们的 GraphQL-BFF 架构设计
GraphQL-BFF 的核心思路是,将多个 services 整合成一个中心化 data graph。
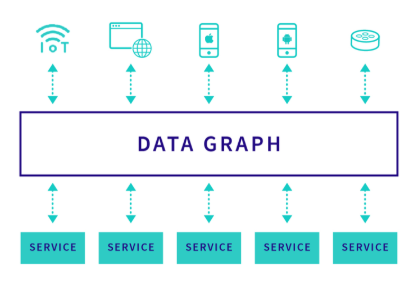
每个 service 的数据结构契约,都放入了一个大而全的 GraphQL Schema 里;如果不做任何模块化和解耦,开发体验将会非常糟糕。每个团队成员,都去修改同一份 Schema 文件。
这明显是不合理的。GraphQL-BFF 的开发模式,应该跟 service 的领域模型,有一一对应的关系。然后通过某种形式,多个 services 自然整合到一起。
因此,我们设计了 GraphQL-Service 的概念。
[7.1.1] GraphQL-Service
GraphQL-Service 是一个由 Schema + Resolver 两部分组成的 JS 模块,它对应基于领域模型的后端的某个 Servcie。每个 GraphQL-Service 应该可以按照模块化的方式编写,跟其它 GraphQL-Service 组合起来后,构建出更大的 GraphQL-Server。
GraphQL-Service 通过 GraphQL 的 Type Extensions 构建数据关联关系。
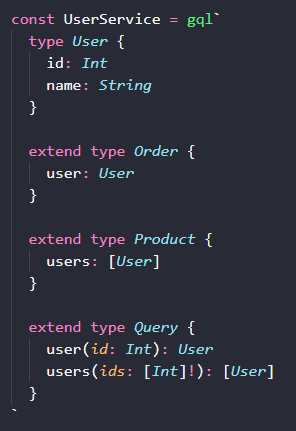
如上所示,我们的 UserService 里面,只涉及到了 User 相关的类型处理。它定义了自己的基本字段,id 和 name。通过 extend type 定义了它在 Order 和 Product 数据里的关联字段,以及定义在 Query 里的入口字段。
从 User Schema 里我们可以看到,User 有两类查询路径。
1)通过根节点 Query 以传递参数的方式,获取到 User 信息。
2)通过 Product 或 Order 节点,以数据关联的方式,获取到 User 信息。

上图是 OrderService 的 Schema,它也只涉及了 Order 相关的类型逻辑。同样是通过 extend type 定义了在 User 和 Product 里的关联字段,以及定义了在根节点 Query 里的入口字段。
Order 数据跟 User 一样,有两种消费路径。一种通过 Query 节点,另一种是通过数据关联节点。
前面我们演示 User, Order 和 Product 铁三角关系时,是在同一个 Schema 里编写它们的关联。我们把多个 GraphQL-Service 的 Schema 整合到一起后,可以生成同样的结果:

上图不是我们手动编写的,而是 merge 多个 GraphQL-Service 的 Schema 后生成的结果。可以看出来,跟之前手写的版本,总体上是一样的。
有了解耦的 Schema 并不足够,它只定义了数据类型及其关联。我们需要 Resolver 去定义数据的具体获取方式,Resolver 也需要解耦。
[7.1.2] GraphQL-Resolver
不管是在官方的 GraphQL 文档里,还是 Apollo-GraphQL 的文档里,Resolver 都是以普通函数的形态出现。

这在简单场景下,没有什么问题。正如在简单场景下,用 node.js 的 http.createServer 就可以创建一个 server。
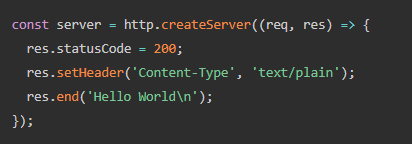
如上,设置状态码,设置响应的 Content-Type,返回内容即可。
然而,在更复杂的真实项目中,我们实际上需要 express、koa 等服务端框架,用中间件的模式编写我们的服务端处理逻辑,由框架将它们整合为一个requestListener 函数,注册到 http.createServer(requestListener) 里。
在 GraphQL Server 里,虽然 endpoint 只有 /graphql 一个,但不代表它只需要一组 Koa 中间件。
正如一开始我们指出的,每个超级接口里都包含一半功能的 GraphQL 实现。GraphQL 是往超级接口的方向更进一步,不能简单地以普通接口的眼光去看待它。
在 Query 下的每个字段,都可能对应 1 到多个内部服务的 API 的调用和处理。只用普通函数构成的 resolverMap,不足以充分表达其中的逻辑复杂度。
不管是用 endpoint 来表示资源,还是用 GraphQL Field 字段来表示资源,它们只是外在形式略有不同,不会改变业务逻辑的复杂度。
因此,采用比普通函数具有更好的表达能力的中间件,组合出一个个 Resolver,再整合到一个 ResolverMap 里。可以更好的解决之前解决不了,或者很难的问题。
所谓的架构能力,体现在理解我们面对的问题的复杂度及其本质特征,并能选择和设计出合适的程序表达模型。
后面我们将演示,正确的架构,如何轻易地克服之前难以解决的问题。
[7.1.3] 用 koa-compose 组织我们的 Resolver
或许很多同学并不清楚,express 或 koa 里的中间件模式,可以脱离作为服务端框架的它们而单独使用。正如 GraphQL 可以单独不作为 server,在任意支持 JavaScript 运行的地方使用一样。
我们将使用 koa-compose 这个 npm 模块,去构造我们的 Resolver。
前文里提到的 gql 函数,接受一个 Schema 返回一个 GraphQL-Service,每个 GraphQL-Service 都有一个 resolve 方法:

resolve 方法,接受两个参数。第一个是 typeName,对应 GraphQL-Schema 里的 Object Type 的类型名称;第二个是 fieldHandlers,每个 handler 支持中间件模式,最终它们将被 koa-compose 整合成一个 Resolver。
以 UserService 为例,其 Resolver 写起来如下:
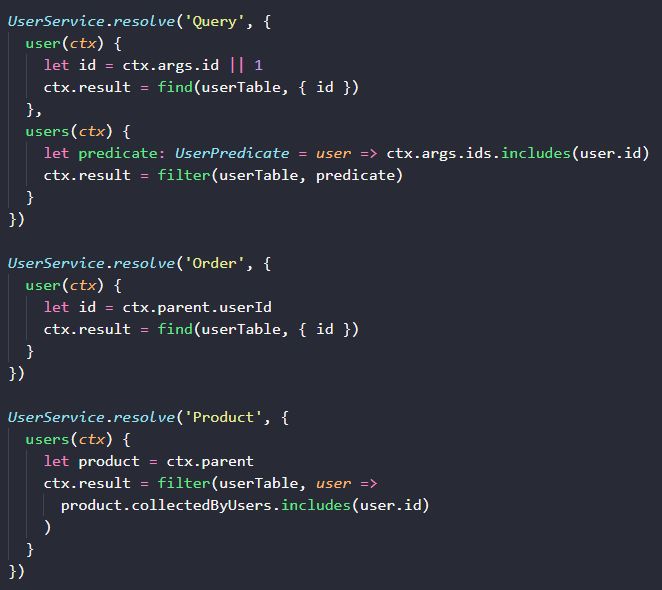
作为普通函数的 Resolver 接收的所有参数,都被整合到了 ctx 里面。ctx.result 则是该字段的最终输出,类似于 koa server 里的 ctx.body。我们刻意采用了 ctx.result 这个不同于 ctx.body 的属性,明确区分我们处理的是一个接口还是一个字段。
在简单场景下,中间件模式的 Resolver 跟普通函数的 Resolver,仅仅是参数的数量和返回值的方式不同。并不会增加大量的代码复杂度。
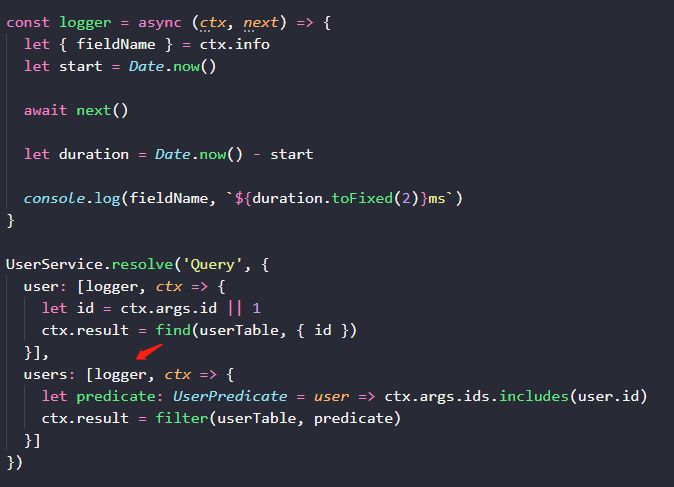
当我们多个字段要复用相同的逻辑时,编写成中间件,然后将 handler 变成数组形式即可。(在代码里我们用 json 模拟了数据库表,所以是同步代码,实际项目里,它可以是异步的调用接口或者查询数据库)。
上面的 logger,只是一个简单案例。除此之外,我们可以编写 requireLogin 中间件,决定一个字段是否只对登陆用户可用。我们可以编写不同的工具型中间件,注入 ctx.fetch, ctx.post, ctx.xxx 等方法,以供后续中间件使用。
每个 GraphQL Field 字段,都拥有独立的一组中间件和 ctx 对象,跟其他字段互相不影响。我们同时,可以把所有字段共享的中间件,放到 koa server 里的中间件里。
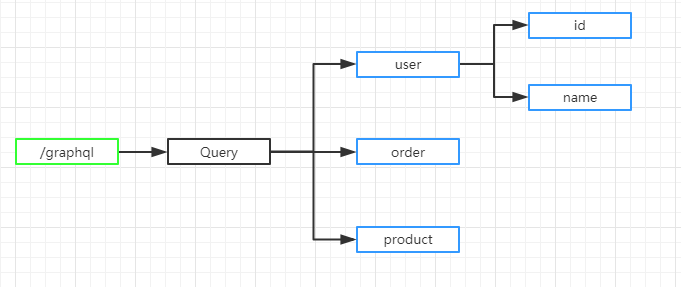
如上图所示,绿框是 endpoint,可以编写 koa server 层面的 middleware。而蓝框是 GraphQL Field 字段,可以编写 Resolver 层面的 middleware。endpoint 层面的 middleware 对 ctx 的修改,会影响到后面所有字段。
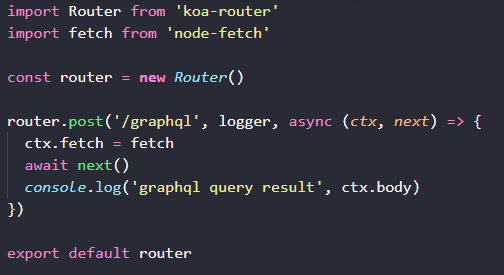
也就是说,我们可以像上面那样。挂接口层面的 logger,可以知道整个 graphql 查询的耗时。编写一个中间件,在 next 之前,挂载一些方法,供后续中间件使用;在 next 之后,拿到 graphql 的查询结果,进行额外的处理。
[7.2] 解决 mock 难题
GraphQL 是天生 mock 友好的模式,因为其 Schema 里已经指明了所有数据的类型及其关联;很容易可以通过 faker data 之类的手段,自动根据类型生成假数据。
然而,在实践中,实现 GraphQL Mocking 还是有不少的挑战。
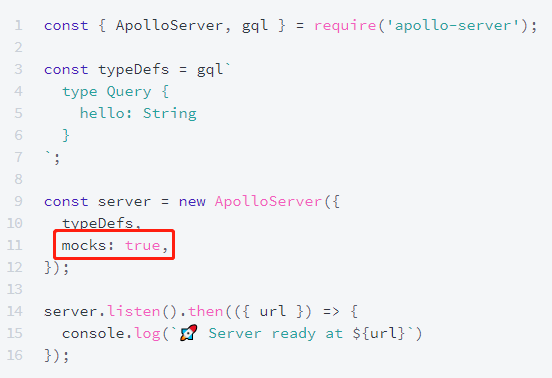
如上图所示,在 Apollo GraphQL 里,mock 看似很简单,只需要在创建服务时,设置 mock 为 true,或者提供一个 mock resolver 即可。但是,一个全局的,跟着服务创建走的 mock,太过粗暴。
mock 的价值在于提供更好的数据灵活性以加速开发效率。它既可以在没有数据时,提供假数据;也可以在真数据的接口有问题时,不用重启服务,也能降级为假数据。它既可以是整个 GraphQL 查询级别的 mock,也可以是字段级别的 mock。
作为超级接口的 GraphQL 服务,全局的,在启动阶段就固化的 mocking,意义不大。
Apollo GraphQL 的 mocking 实践问题,正是它采用普通函数来描述 Resolver 所带来的;它很难简单的通过拓展某个 resolver 而支持 mocking。它不得不在创建服务时,额外新增一个 mock resolver map 去承担 mocking 职能。
而我们的 composed resolver 处理动态 mocking 却异常简单。

它不仅可以在运行时动态确定,它不仅可以细化到字段级别,它甚至可以跟着某次查询走 mock 逻辑(通过添加 @mock 指令)。

上图是默认情况下,基于 faker 这个 npm 包,根据数据类型生成的 mock data。

在我们的设计里,默认的 mocking,其内部实现方式很简单。我们先是编写了上图,根据 GraphQL Type 调用 faker 模块对应的方法,生成假数据。
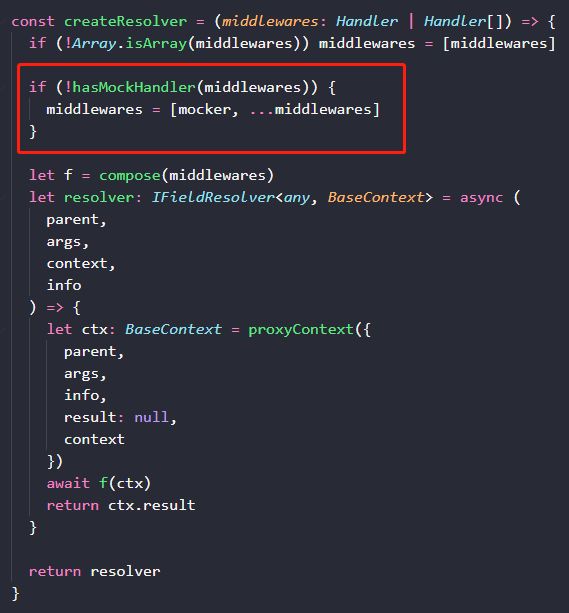
然后在 createResolver 这个将中间件整合成 resolver 的函数里,先判断中间件里是否存在自定义的 mock handler 函数,如果没有,就追加前面编写的 mocker 处理函数。
我们还提供了 mock 中间件,让开发者能指定 mock 数据来源,比如指定 mock json 文件。
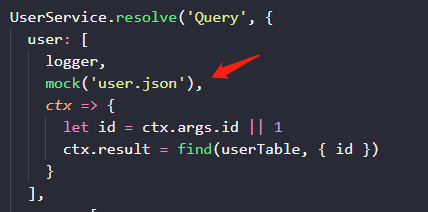
mock 中间件,接收字符串参数时,它会搜寻本地的 mock 目录下是否有同名文件,作为当前字段的返回值。它也接收函数作为参数,在该函数里,我们可以手动编写更复杂的 mock 数据逻辑。
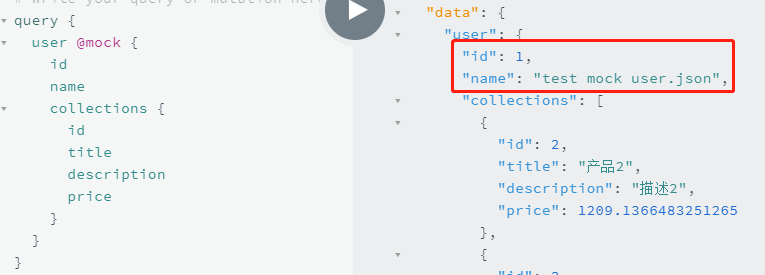
有趣的地方是,mock/user.json 文件里,只包含上图红框的数据,其关联出来的 collections 字段,是真实的。这是合理的做法,mock 应该跟着 resolver 走。关联字段拥有自己的 resolver,可能调用自己的接口;不应该因为父节点是 mock 的,子节点也进入 mock 模式。
如此,我们可以在父节点 resolver 对应的后端接口挂掉后,mock 它,让没挂掉的子节点 resolver 正常运行。如果我们希望子节点 resolver 也进入 mock。很简单,添加一个 @mock 指令即可。
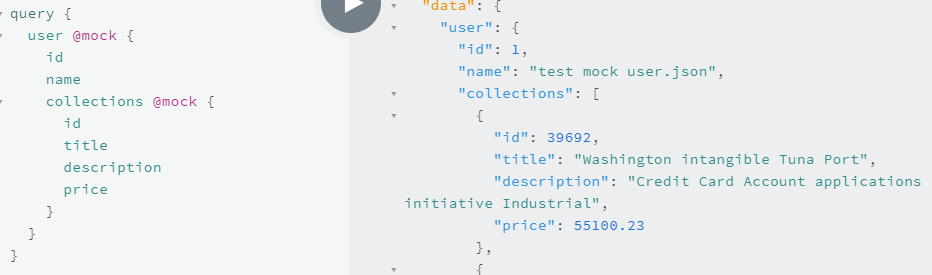
如上所示,user 字段和 collections 字段的 resolver 都进入了 mock 模式。
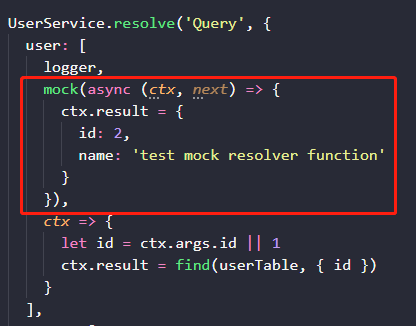
自定义 mock resolver 函数的方式如上图所示,mock 中间件保证了,只有在该字段进入 mock 模式时,才执行 mock resolver function。并且,mock resolver function 内部依然有机会通过调用 next 函数,触发后面的真实数据获取逻辑。
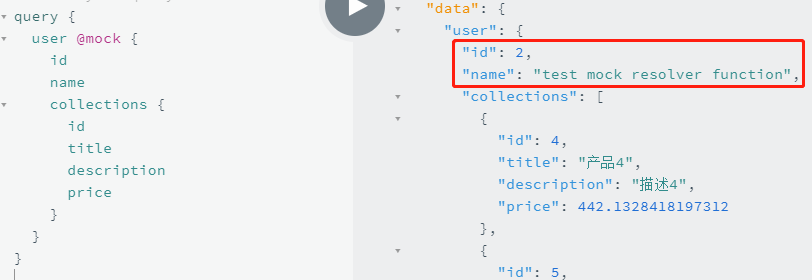
以上所有这些灵活性,都来自于我们选用了表达能力和可组合性更好的中间件模式,代替普通该函数,承担 resolver 的职能。
总结
至此,我们得到了一个简单而灵活的实践模式。我们用 Schema 去构建 Data Graph 数据关联图,我们用 Middleware 去构建 Resolver Map,它们都具备很强的表达能力。
在开发 GraphQL-BFF 时,我们的 GraphQL-Service 跟后端基于领域模型的 Service,具有总体上的一一对应关系。不会产生后端数据层解耦后,在 GraphQL 层重新耦合的尴尬现象。
关于 GraphQL 还有很多话题可以讨论,比如 batching , caching 等。这部分内容在网络上很多 GraphQL 的文档和教程里都可以找到,这里我们不再赘述。
总的而言,根据我们对 GraphQL 的考察和实践,我们认为它可以比 RESTful API 更好的解决我们面对的问题。
我们对 GraphQL 的期望,不仅仅停留在 BFF 层。我们希望通过积累在 BFF 层使用 GraphQL 的成功经验,帮助我们摸索出在 Micro Frontend 架构上使用 GraphQL 模式的合理设计。
如前面所演示的,像 User,Product 和 Order 这种公共级别的数据类型,不可能只由一个团队去维护,它们需要被其它团队所拓展。使得我们可以通过用户,找到它关联的订单,收藏,优惠券等由其它团队维护的数据。
放到 Micro Frontend 架构上,一个支付按钮,也夹杂了多种类型的数据,产品信息,用户信息,库存信息,UI 展示信息,交互状态信息等等,综合了这些信息,支付按钮被点击时,才得到了充分的数据,可以决定是否去支付。
朴素 Micro Frontend 的设计,用 Vue, React, Angular 不同框架,分别维护不同组件,通过 router/message-passing 等方式互相通讯。在我看来,这是对后端微服务架构的拙劣模仿。
后端服务,各自部署在独立环境中,对体积不敏感;因而可以采用不同的语言和技术栈。这不意味着将它简单的放到前端里一样成立。无法共享前端开发的基础设施,这不是微前端,这是一种人员组织架构上的混乱。
GraphQL 让我们看到,基于领域模型的微前端架构,可能是更好的方向。一个简单的支付按钮,也综合了多个领域模型,由多个开发者有组织的协同开发。并不因为它表面上看起来是一个 Button 组件,就由某个团队单独维护。
当然,探索 GraphQL 的其它方向的前提是,GraphQL-BFF 架构得到成功的验证。就现阶段的实践成果来看,我们对此充满了信心。
尽管我们的代码暂无开源计划,不过相信这篇文章,足够完整和清楚地介绍了我们的 GraphQL-BFF 方案。希望它能给大家带来一点帮助。
完
往期 精彩回顾 Nealyang 全栈前端Flutter 从入门到寄几玩儿
Decorator 从原理到实战 一年半工作经验如何拿下阿里、滴滴、网易 offer

 戳 “阅读原文”,获取原文地址(能查阅外链)“ 在看”的永远18岁~
戳 “阅读原文”,获取原文地址(能查阅外链)“ 在看”的永远18岁~ 
标签:
相关文章
-
无相关信息