(转)初学node.js有感一
Node.js感悟
一、前言
很久以前就对node.js十分的好奇和感兴趣,因为种种原因没能去深入的认识了解和学习掌握这门技术,最近正好要做一些项目,其中就用到了node.js中的一些东西,所以借着使用的时间来对node.js进行一些剖析,每一种语言都有自己的理念和设计初衷,但是万变不离其宗,最终还是要归结到编译和执行,对于一门新的语言,我们不要急着去记忆语法,最好的方式就是通过问题的形式去不断的积累经验,自然而然的那些语法,特殊思想就渐渐地熟能生巧了,万事开头难,任何东西到了一定的程度之后都是殊途同归的,本人也学习了很多语言,解释性语言和执行性语言遇到的也比较多,对于node.js在这里就将我自己的学习过程和经验记录下来,一方面是为了以后的查阅和学习,另一方面是为广大的IT界网友的知识库中增砖添瓦,好了,闲言休谈,直入主题!
二、node.js的性质、优缺点和适用范围
Node.js是一个专注于实现高性能Web服务器优化的专家,几经探索,几经挫折后,遇到V8而诞生的项目。Node.js是一个让JavaScript运行在服务器端的开发平台,它让JavaScript的触角伸到了服务器端,可以与PHP、JSP、Python、Ruby平起平坐。但Node似乎有点不同:Node.js不是一种独立的语言,与PHP、JSP、Python、Perl、Ruby的“既是语言,也是平台”不同,Node.js的使用JavaScript进行编程,运行在JavaScript引擎上(V8)。与PHP、JSP等相比(PHP、JSP、.net都需要运行在服务器程序上,Apache、Naginx、Tomcat、IIS。),Node.js跳过了Apache、Naginx、IIS等HTTP服务器,它自己不用建设在任何服务器软件之上。Node.js的许多设计理念与经典架构(LAMP = Linux + Apache + MySQL + PHP)有着很大的不同,可以提供强大的伸缩能力。Node.js没有web容器。Node.js自身哲学,是花最小的硬件成本,追求更高的并发,更高的处理性能。
单线程:在Java、PHP或者.net等服务器端语言中,会为每一个客户端连接创建一个新的线程,而每个线程需要耗费大约2MB内存,理论上一个8GB内存的服务器可以同时连接的最大用户数为4000个左右。要让Web应用程序支持更多的用户,就需要增加服务器的数量,而Web应用程序的硬件成本当然就上升了。Node.js不为每个客户连接创建一个新的线程,而仅仅使用一个线程。当有用户连接了,就触发一个内部事件,通过非阻塞I/O、事件驱动机制,让Node.js程序宏观上也是并行的。使用Node.js,一个8GB内存的服务器,可以同时处理超过4万用户的连接。另外,单线程的带来的好处,还有操作系统完全不再有线程创建、销毁的时间开销。
非阻塞I/O:因为CPU的效率是远远高于I/O设备的执行效率的,如果让CPU去等待I/O的执行,将会极大地浪费时间,降低性能,比如在访问数据库或者读文件的时候,在传统的单线程处理机制中,在执行了访问数据库或文件代码之后,整个线程都将暂停下来(阻塞I/O),等待数据库或者文件系统返回结果才能执行后面的代码。I/O阻塞了代码的执行极大地降低了程序的执行效率。由于Node.js中采用了非阻塞型I/O机制,因此在执行了访问数据库或文件的代码之后,将立即转而执行其他代码,把返回结果的处理代码放在回调函数中,从而提高了程序的执行效率。当某个I/O执行完毕时,将以事件的形式通知执行I/O操作的线程,线程执行这个事件的回调函数。为了处理异步I/O,线程必须有事件循环,不断的检查有没有未处理的事件,依次予以处理。阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程。而非阻塞模式下,一个线程永远在执行计算操作,这个线程的CPU核心利用率永远是100%。所以,这是一种特别有哲理的解决方案:与其人多,但是好多人闲着;还不如一个人玩命,往死里干活儿。
事件驱动:在Node中,客户端请求建立连接,提交数据等行为,会触发相应的事件。在Node中,在一个时刻,只能执行一个事件回调函数,但是在执行一个事件回调函数的中途,可以转而处理其他事件,然后返回继续执行原事件的回调函数,这种处理机制,称为“事件环”机制。Node.js底层是C++(V8也是C++写的),底层代码中,近半数都用于事件队列、回调函数队列的构建。
优缺点:因为单线程,在处理大规模并发的任务中还是会显得力不从心的,比如在CPU密集型事务中就会遇到瓶颈,另外就是node.js是没有web容器的,代码直接没有根目录的说法,在一定程度上为程序员增加了代码量,但也提高了灵活性,为高级路由带来了极大的方便,在node.js中回调函数会有很深的层次,为代码的阅读多多少少造成了一定的障碍。善于处理异步事件(callback),处理同步事务中需要额外的负担。
适用范围:当应用程序需要处理大量并发的I/O,而在向客户端发出响应之前,应用程序内部并不需要进行非常复杂的处理的时候,Node.js非常适合。Node.js也非常适合与web socket配合,开发长连接的实时交互应用程序。比如:用户表单收集、考试系统、聊天室、图文直播、提供JSON的API(为前台Angular使用)。
三、部署环境
node.js类似于Java,和Java的虚拟机原理有点相似可以在Linux和Windows机器上运行,但是编程的方式和细微之处还是有差异的,这里主要从Windows的环境中来理解,因为本质上还是语言的设计思想是我们的着重点和兴趣点!
1,下载node.js
这是非常简单的一件事情,可以在https://nodejs.org/en/download/上方便的下载适合自己电脑的版本,这里我们使用Windows平台。
2,安装node.js
只需双击即可完成安装,在这里建议不要将路径放到C盘,这是一种安装软件的共识。并且在安装的过程中,安装向导已经帮我们完成了环境变量的注册,我们可以通过环境变量来查看,这点很浅显,不必再说。
3,下载sublime
因为node.js非常的轻量级,差不多10MB左右,原生的环境是没有GUI的,我们可以先在文本编辑器中编写代码,在这里当然是推荐sublime了,当然notebook也不错~~
四、编写简单的程序——hello,world!
 View Code
View Code
编写了.js的程序,运行的时候就要通过node.js来运行了,首先在CMD中切换到编写程序的目录下,当然也可以不用。然后用node XXX.js即可启动服务。然后在浏览器中(建议用Firefox)输入相应的监听IP地址加上端口号,这里的端口号使用比较大一点的就可以,因为是回环测试,所以使用127.0.0.1来作为测试IP。
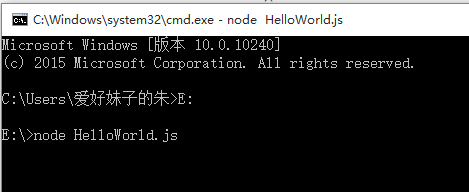
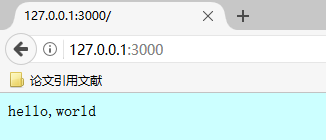
这样一个简单的程序就运行成功了,回顾一下,我们其实是用node.js搭建了一个服务器,然后来监听端口的访问事件,最后做出相应的回应,这样一个简单的例子其实是非常有用的,毕竟我们的服务器已经可以工作了,但是这样也有许多缺陷,比如我们关闭CMD之后服务就关闭了,比如我们运行一次程序需要的过程十分繁琐,这些都会在以后得到解决!
注意:在node.js中必须使用res.end()函数来返回,不然的话浏览器会认为服务器还没有结束本次的数据传输,而一直进入忙等状态,这点值得警醒,另外,require和C语言中的include很像,都是导入相应的包。
五、node.js没有web容器,访问的文件路径和url可能关系不大
View Code
上面的代码就是说明这样的一种情况,当用户输入了URL之后进行处理的时候,node.js可以对URL进行解析并且按照自己设定好的路径来根据相应的字段找到可能是有着好几个文件夹下的一个文件,这个文件的文件名可能与url中的字段完全不同,也就是说可以把字段看做一个地址(指针),指向相应的文件所在的物理位置!

1 if(req.url == "/fang"){
2 fs.readFile("./test/xixi.html",function(err,data){
3 //req表示请求,request; res表示响应,response
4 //设置HTTP头部,状态码是200,文件类型是html,字符集是utf8
5 res.writeHead(200,{"Content-type":"text/html;charset=UTF-8"});
6 res.end(data);
7 });
8 }
比如上面的代码,明明URL是IP+/fang,可是在返回数据的时候将当前目录下的test文件夹下的xixi.html文件作为返回对象。为网站的路由设计提供了极大的便利。
六、对URL解析
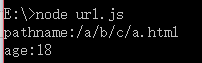
6.1、解析URL案例
1 var http = require("http");2 var url = require("url");3 4 var server = http.createServer(function(req,res){5 //url.parse()可以将一个完整的URL地址,分为很多部分:6 //host、port、pathname、path、query7 var pathname = url.parse(req.url).pathname;8 //url.parse()如果第二个参数是true,那么就可以将所有的查询变为对象9 //就可以直接打点得到这个参数
10 var query = url.parse(req.url,true).query;
11 //直接打点得到这个参数
12 var age = query.age;
13 console.log("pathname:" + pathname);
14 console.log("age:" + age);
15 res.end();
16 });
17 server.listen(3000,"127.0.0.1");
运行结果:

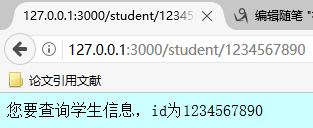
6.2、通过正则表达式来解析URL并设计路由
eg:通过输入的信息的不同选择跳转到不同的界面
1 var http = require("http");2 3 var server = http.createServer(function(req,res){4 //得到url5 var userurl = req.url;6 7 res.writeHead(200,{"Content-Type":"text/html;charset=UTF8"})8 //substr函数来判断此时的开头9 if(userurl.substr(0,9) == "/student/"){
10 var studentid = userurl.substr(9);
11 console.log(studentid);
12 if(/^d{10}$/.test(studentid)){
13 res.end("您要查询学生信息,id为" + studentid);
14 }else{
15 res.end("学生学号位数不对");
16 }
17 }else if(userurl.substr(0,9) == "/teacher/"){
18 var teacherid = userurl.substr(9);
19 if(/^d{6}$/.test(teacherid)){
20 res.end("您要查询老师信息,id为" + teacherid);
21 }else{
22 res.end("老师学号位数不对");
23 }
24 }else{
25 res.end("请检查url");
26 }
27 });
28
29 server.listen(3000,"127.0.0.1");
测试结果:
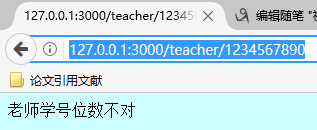
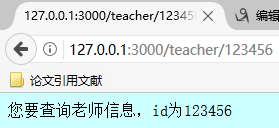
![]()
七、表单提交
服务器代码:
1 var http = require("http");2 var url = require("url");3 4 var server = http.createServer(function(req,res){5 //得到查询部分,由于写了true,那么就是一个对象6 var queryObj = url.parse(req.url,true).query;7 var name = queryObj.name;8 var age = queryObj.age;9 var sex = queryObj.sex;
10 res.writeHead(200,{"Content-Type":"text/html;charset=UTF-8"});
11 res.end("服务器收到了表单请求" + name + age + sex);
12 });
13
14 server.listen(3000,"127.0.0.1");
浏览器代码:
1 2 3 4 516 17Document 6 7 8
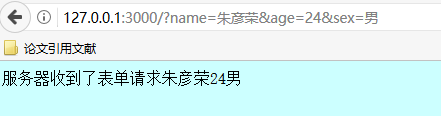
八、事件环机制——多用户访问导致的异步现象
因为node.js是单线程的,所以同一时刻有大量用户在访问的时候,而且是在做读文件的I/O操作的时候,因为非阻塞的性质,此时单线程回去处理其他事情,也就是去处理其他用户的请求,等文件读取完毕了,再通过外设来以事件的形式通知CPU响应并处理!下图的运行结果并没有反应该性质,是因为自己的手速怎么能比得上计算机的处理效率呢,如果多台电脑(浏览器)同时访问,那肯定会出现次序的混乱的。
1 var http = require("http");2 var fs = require("fs");3 4 var server = http.createServer(function(req,res){5 //不处理小图标6 if(req.url == "/favicon.ico"){7 return;8 }9 //给用户加一个五位数的id
10 var userid = parseInt(Math.random() * 89999) + 10000;
11
12 console.log("欢迎" + userid);
13
14 res.writeHead(200,{"Content-Type":"text/html;charset=UTF8"});
15 //两个参数,第一个是完整路径,当前目录写./
16 //第二个参数,就是回调函数,表示文件读取成功之后,做的事情
17 fs.readFile("./1.txt",function(err,data){
18 if(err){
19 throw err;
20 }
21 console.log(userid + "文件读取完毕");
22 res.end(data);
23 });
24 });
25
26 server.listen(3000,"127.0.0.1");

九、通过API来创建文件,并且知道自己读取的是一个文件还是文件夹
任务一:简单的判断文件是不是文件夹
1 var http = require("http");2 var fs = require("fs");3 4 var server = http.createServer(function(req,res){5 //不处理小图标6 if(req.url == "/favicon.ico"){7 return;8 }9 fs.mkdir("./album");
10 fs.mkdir("./album/aaa");
11 //stat检测状态
12 fs.stat("./album/aaa",function(err,data){
13 //检测这个路径,是不是一个文件夹
14 console.log(data.isDirectory());
15 });
16 res.end();
17 });
18
19 server.listen(3000,"127.0.0.1");
任务二:读取一个文件目录下的所有文件夹并且显示出来
方法一:思考为什么会失败!!!
1 var http = require("http");2 var fs = require("fs");3 4 var server = http.createServer(function(req,res){5 //不处理小图标6 if(req.url == "/favicon.ico"){7 return;8 }9 //存储所有的文件夹
10 var folder = [];
11 //stat检测状态
12 fs.readdir("./album",function(err,files){
13 //files是个文件名的数组,并不是文件的数组,表示./album这个文件夹中的所有东西
14 //包括文件、文件夹
15 for(var i = 0 ; i < files.length ;i++){
16 var thefilename = files[i];
17 //又要进行一次检测
18 fs.stat("./album/" + thefilename , function(err,stats){
19 //如果他是一个文件夹,那么输出它:
20 if(stats.isDirectory()){
21 folder.push(thefilename);
22 }
23 console.log(folder);
24 });
25 }
26 });
27 });
28
29 server.listen(3000,"127.0.0.1");
运行结果:
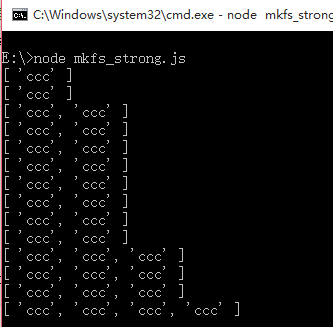
分析,根据代码是调用了API将目录通过数组的形式读出来,并且显示出来,可是为什么只显示了文件夹“ccc”,而没有其他的文件夹呢,到这里我们就能理解node.js的编程精髓之一了,那就是异步性,读取文件夹也是一种I/O操作,势必就要被阻塞,我们是使用for循环来读取的,当调用fs.readdir()得到了正确的结果,文件列表信息,其中包括了文件和文件夹之后执行回调函数,此时我们需要进行筛选操作,这个时候我们需要再次进行一次I/O操作,而for循环(CPU)是不等我们的I/O设备的操作的,这个时候当一个I/O操作刚执行完的时候,得到了aaa是一个文件夹,但是因为在启动这个I/O操作的过程中,CPU必定已经执行了很多个循环了,变量thefilename早已经变成了其他的数值,至于为什么会变成ccc,那是因为CPU执行的速度太快了,早就跳到了数组的最后一个,而只有是文件夹才会被记录,所以不会是其他的文件,一定是一个文件夹名,同样的其他两个文件夹也是当I/o完成的时候thefilename早就变成了ccc了,所以输出的结果是这个样子,在这里我们需要注意一点,这点非常重要,就是在标题八中不同用户的访问,虽然次序会变乱,可是最后还是能将欢迎userID和userID读取完毕一一对应上,也就是说userID这个变量在每一个浏览器访问的时候都是另外开辟了一个新空间,而在一台电脑上进行的for循环,thefilename却没有那样的好运,总是会被替换掉,彻底的替换掉,要不然的话结果将不会是全是“ccc”,也就是说thefilename没有开辟新的内存空间,关于这一点可能涉及到变量的定义范围,有效范围,命名空间,编译原理的优化和操作系统,计算机网络等相关的学科,值得深究和理解!!!!!!
那么如何解决这样的问题呢,我们没有得到自己想要的东西,这个时候就要用到原子操作了,而node.js里面使用了iterator迭代器来巧妙地实现了原子操作!!!
方法二:
1 var http = require("http");2 var fs = require("fs");3 4 var server = http.createServer(function(req,res){5 //不处理收藏夹小图标6 if(req.url == "/favicon.ico"){7 return;8 }9 //遍历album里面的所有文件、文件夹
10 fs.readdir("./album/",function(err,files){
11 //files : ["0.jpg","1.jpg" ……,"aaa","bbb"];
12 //files是一个存放文件(夹)名的数组
13 //存放文件夹的数组
14 var folder = [];
15 //迭代器就是强行把异步的函数,变成同步的函数
16 //1做完了,再做2;2做完了,再做3
17 (function iterator(i){
18 //遍历结束
19 if(i == files.length){
20 console.log(folder);
21 return;
22 }
23 fs.stat("./album/" + files[i],function(err,stats){
24 //检测成功之后做的事情
25 if(stats.isDirectory()){
26 //如果是文件夹,那么放入数组。不是,什么也不做。
27 folder.push(files[i]);
28 }
29 iterator(i+1);
30 });
31 })(0);
32 });
33 res.end();
34 });
35
36 server.listen(3000,"127.0.0.1");
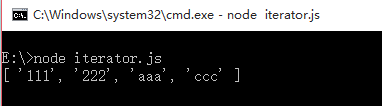
通过迭代器,递归的形式,我们可以很好的让一个操作完成之后在执行其他的操作,这样其实就相当于原子操作,要么一起完成,要么就不完成,以失败告终,这样其中的变量等数据就不用去考虑是不是被覆盖的情况了!!!!!!如下所示,这次正确输出结果!!!!!!
运行结果:
十、对于不同的文件类型,正确的显示相应的文件
在node.js中是没有web容器的概念的,这样容器需要完成的很多事情就需要我们自己去完成了,正因为这样我们需要了解更多的底层的东西!!!
1 var http = require("http");2 var url = require("url");3 var fs = require("fs");4 var path = require("path");5 6 http.createServer(function(req,res){7 //得到用户的路径8 var pathname = url.parse(req.url).pathname;9 //默认首页
10 if(pathname == "/"){
11 pathname = "index.html";
12 }
13 //拓展名
14 var extname = path.extname(pathname);
15
16 //真的读取这个文件
17 fs.readFile("./static/" + pathname,function(err,data){
18 if(err){
19 //如果此文件不存在,就应该用404返回
20 fs.readFile("./static/404.html",function(err,data){
21 res.writeHead(404,{"Content-type":"text/html;charset=UTF8"});
22 res.end(data);
23 });
24 return;
25 };
26 //MIME类型,就是
27 //网页文件: text/html
28 //jpg文件 : image/jpg
29 var mime = getMime(extname);
30 res.writeHead(200,{"Content-type":mime});
31 res.end(data);
32 });
33
34 }).listen(3000,"127.0.0.1");
35
36 function getMime(extname){
37 switch(extname){
38 case ".html" :
39 return "text/html";
40 break;
41 case ".jpg" :
42 return "image/jpg";
43 break;
44 case ".css":
45 return "text/css";
46 break;
47 }
48 }
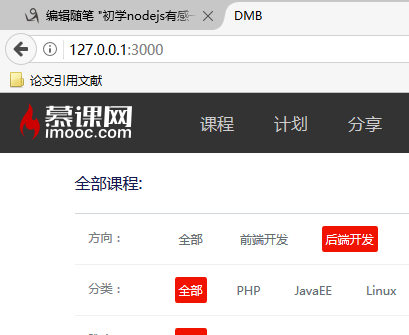
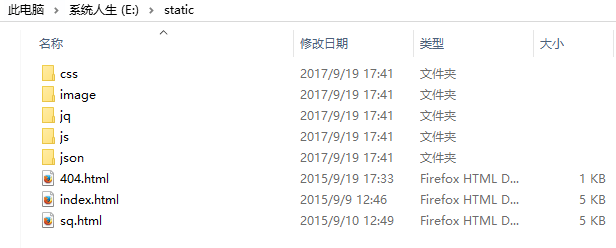
其中getMime()就是对不同类型进行处理的函数!!!
十一、总结
总算是写完了这么长的文章,很多东西都是要在实践中去掌握的,特别是技术类的东西,在对node.js的探索中,我们已经慢慢的触摸到了门槛了,在接下来的学习中我们会对node.js有更加深刻的认识和使用!
标签:
相关文章
-
无相关信息